1.1 智能体的由来与大语言模型的发展
什么是智能体
想象你是一名研究员,负责分析某个行业。你每天需要:阅读文献和资料(感知信息)、分析数据和现象(推理判断)、撰写研究报告(输出行动)、根据反馈改进方法(学习提升)。金融分析师、管理咨询师、市场研究员都是这样工作的。
AI 智能体做的事情和你一样。根据人工智能经典教材的定义,智能体(Agent)是通过传感器感知环境、通过执行器作用于环境的实体。用更直白的话说,智能体能够自主地感知、思考、行动和学习。
这四种能力构成了智能体的核心特征:
- 感知(Perception):获取环境信息,比如阅读文档、接收用户指令
- 推理(Reasoning):基于知识和目标进行思考判断
- 行动(Action):执行操作改变环境,比如生成报告、调用工具
- 学习(Learning):从经验中改进自身表现
理解这四个能力,是理解整本书的基础。
七十年演进:从图灵测试到 ChatGPT
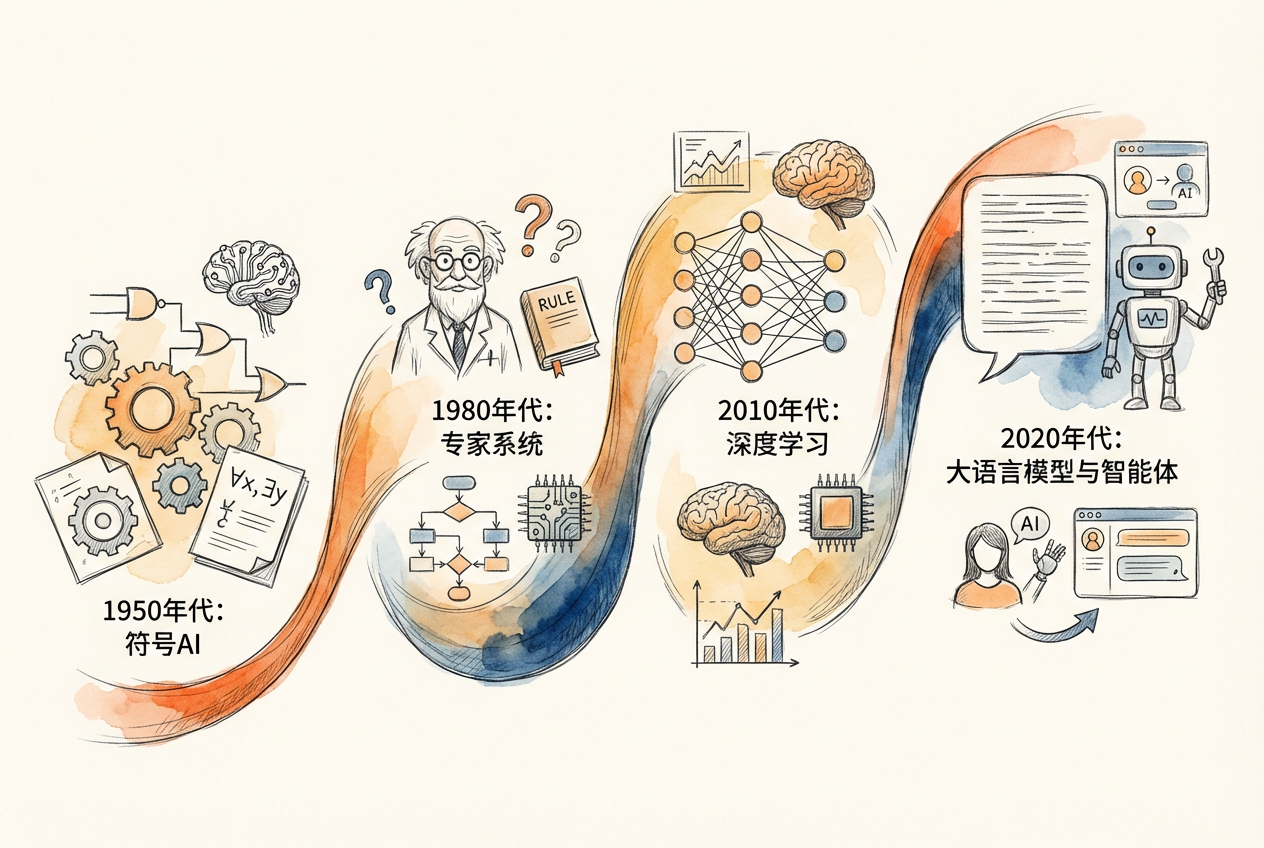
智能体的概念并非凭空出现。它的发展历程,折射出人工智能七十年的探索与突破。
1950 年代:AI 的诞生
1950 年,英国数学家图灵发表论文《计算机器与智能》,提出了著名的图灵测试:如果人类无法区分对话者是人还是机器,就认为这台机器具有智能。这个思想实验将哲学层面的智能讨论转化为可操作的实验范式。
1956 年夏天,麦卡锡、明斯基等人在达特茅斯学院召开研讨会,正式提出人工智能这一术语。会议提出一个大胆的主张:智能的任何方面原则上都可以被精确描述,从而让机器模拟。这次会议标志着 AI 作为独立学科的诞生。
1970-1980 年代:专家系统的黄金时代
早期 AI 研究者相信,智能可以通过符号和规则来实现。他们开发了一系列专家系统(Expert System),试图将人类专家的知识编码进计算机。
最著名的例子是 MYCIN,一个医疗诊断系统。它用约 600 条规则构成知识库,能够诊断细菌感染并推荐抗生素治疗方案。在测试中,它的诊断准确率达到 65%,优于部分非专业医生。MYCIN 还开创了解释子系统——它能说明自己为什么做出某个诊断,这是可解释 AI 的早期形态。
但专家系统有致命弱点:知识获取困难,维护成本高昂,而且一旦超出预设知识范围,性能就急剧下降。到 1980 年代末,AI 研究陷入第二次寒冬。
1987 年:意图理论与 BDI 模型
就在 AI 研究低迷之际,哲学家 Bratman 提出了意图理论,后来被形式化为 BDI 模型(Belief-Desire-Intention,信念-愿望-意图)。这个模型描述了理性智能体如何做决策:
- 信念:智能体对世界状态的认知
- 愿望:智能体希望达成的目标
- 意图:智能体承诺执行的行动计划
用投资经理的工作来理解:他观察市场变化、更新对市场状态的判断(信念);根据判断和投资目标,列出可能的方案(愿望);权衡利弊后选择要执行的方案(意图);然后制定操作步骤并执行。
这种观察-思考-决策-执行的循环,正是后来大语言模型智能体的思维原型。
2016 年:AlphaGo 的里程碑
2016 年 3 月,DeepMind 的 AlphaGo 以 4:1 击败围棋世界冠军李世石。这是 AI 发展史上的标志性事件。
围棋的可能局面数量超过宇宙中原子的总数,传统穷举搜索完全不可行。AlphaGo 结合了深度神经网络和强化学习:用策略网络学习人类棋手的落子模式,用价值网络评估棋局胜率,通过自我对弈不断提升。它证明了 AI 在极其复杂的决策任务中可以达到甚至超越人类顶尖水平。
2017 年:Transformer 架构的突破
2017 年,Google 研究团队发表论文《Attention Is All You Need》,提出 Transformer 架构。这项技术创新为后续所有大语言模型奠定了基础。
Transformer 的核心是自注意力机制(Self-Attention),允许模型在处理文本时同时关注所有位置的信息,而不是像传统方法那样逐字处理。这使得模型能够更好地理解语言中的长距离依赖关系。
2018-2022 年:大语言模型的崛起
基于 Transformer 架构,OpenAI 发布了 GPT 系列模型:
- GPT-1(2018):1.17 亿参数,首次展示预训练-微调范式
- GPT-2(2019):15 亿参数,展现令人惊讶的文本生成能力
- GPT-3(2020):拥有 1750 亿参数,首次展示上下文学习能力——不需要微调,只需要在提示中给几个例子,模型就能学会新任务
研究者发现了两个关键现象。规模法则:模型性能随参数量、数据量和计算量的增加呈幂律增长。涌现能力:当模型规模超过某个阈值时,会突然展现出小模型不具备的能力,比如逻辑推理、代码生成。
2022 年 11 月,ChatGPT 发布。它基于 GPT-3.5,采用人类反馈强化学习(RLHF)优化,使模型更符合人类偏好。ChatGPT 的成功不仅在于技术,更在于产品形态——它让普通人第一次能够通过自然对话与强大的 AI 交互。
2022 年至今:从语言模型到智能体
ChatGPT 之后,AI 领域的焦点开始从单纯的对话转向智能体。
2022 年,Yao 等人提出 ReAct 框架(Reasoning + Acting),将推理和行动交织进行。模型在回答问题时,会先思考(Thought),然后执行行动(Action),观察结果(Observation),再继续思考。这种模式让 AI 能够调用外部工具获取信息,弥补自身知识的局限。
2023 年,AutoGPT 项目爆火,展示了 AI 自主设定子目标、执行任务链的可能性。虽然它还不够成熟,但让公众看到了自主智能体的潜力。
2024-2025 年,开源社区涌现出一批终端 AI 编码智能体,其中 Opencode 是代表之一——它在终端中运行,支持 75+ 大语言模型提供商,能理解整个代码库的上下文,执行文件操作、运行命令,还能通过 MCP 协议调用外部工具。Opencode 代表了 AI 智能体从研究走向实用的重要一步,也是本书的核心教学工具。
大语言模型(Large Language Model,LLM)是一类基于 Transformer 架构、经过大规模文本训练的神经网络模型。它们能够理解和生成自然语言,是当代 AI 智能体的认知核心。代表模型包括 OpenAI 的 GPT 系列、Anthropic 的 Claude 系列、Google 的 Gemini 系列。
为什么 LLM 改变了一切
大语言模型之所以能成为智能体的核心,是因为它带来了几项关键能力:
通用知识:通过海量文本的预训练,LLM 获得了广泛的世界知识。它懂金融、懂经济学、懂历史、懂编程,虽然不是每个领域都精通,但基础知识面极广。
自然语言接口:你不需要学习编程语言,用日常的话就能与 AI 交流。这大大降低了使用门槛。
上下文学习:在对话中给 AI 几个例子,它就能学会新任务的模式。不需要重新训练模型。
推理能力:通过链式思考(Chain-of-Thought)等技术,LLM 能够分步骤推理复杂问题。
传统软件是确定性的:同样的输入必然产生同样的输出。LLM 驱动的智能体则完全不同——它们具有概率性和灵活性,能理解模糊的需求,在没有明确规则的情况下做出判断。这正是经济金融领域许多任务所需要的能力——分析师的工作充满不确定性,需要判断而非机械执行。
| 特征 | 传统软件系统 | LLM 智能体系统 |
|---|---|---|
| 执行方式 | 确定性规则 | 概率性推理 |
| 输入形式 | 结构化数据 | 自然语言 |
| 任务适应 | 需要重新编程 | 通过提示词调整 |
| 知识来源 | 显式编码 | 预训练 + 检索增强 |
| 适用场景 | 规则明确的任务 | 需要判断的任务 |