8.1 从工具调用到技能系统
第 7 章介绍了智能体的工具使用能力。通过 Function Calling 和 MCP 协议,智能体可以查询数据库、调用 API、操作文件系统。这些能力让智能体从纯文本推理走向与外部世界交互。
但工具调用机制存在一个容易被忽视的成本问题:上下文空间消耗。本节将从这一问题出发,引出 Agent Skills 的设计动机和技术本质。
8.1.1 工具调用的上下文成本
每一次工具调用都需要模型理解工具的定义。定义包括工具名称、功能描述、参数列表及其类型约束。这些信息以 JSON Schema 格式存在,必须加载到模型的上下文窗口中。
以一个查询股票行情的工具为例,其定义大致如下:
{
"name": "get_stock_quote",
"description": "获取指定股票的实时行情数据",
"inputSchema": {
"type": "object",
"properties": {
"symbol": {
"type": "string",
"description": "股票代码,如 AAPL、600519.SH"
},
"fields": {
"type": "array",
"items": { "type": "string" },
"description": "需要的字段:price, volume, change, pe_ratio 等"
},
"currency": {
"type": "string",
"enum": ["USD", "CNY", "HKD"],
"description": "报价货币"
}
},
"required": ["symbol"]
}
}这个仅有 3 个参数的工具定义,已经消耗约 150-200 tokens。一个中等复杂度的工具(5-8 个参数)通常消耗 200-500 tokens。
单个工具的消耗看起来不大。问题在于规模化之后的累积效应。
8.1.2 MCP 的全量加载问题
MCP 协议的设计是:当智能体连接一个 MCP Server 时,该 Server 将所有可用工具的定义一次性推送到模型上下文中。智能体不能选择只加载其中几个——要么全部接收,要么不连接。
下表展示了不同规模的 MCP Server 带来的上下文开销:
| MCP Server 规模 | 工具数量 | 估算 Token 消耗 | 占 128K 上下文比例 |
|---|---|---|---|
| 轻量级(如天气查询) | 2-3 个 | 400-900 | 0.3%-0.7% |
| 中等(如金融数据) | 8-12 个 | 2,000-4,000 | 1.6%-3.1% |
| 重量级(如企业 ERP) | 20-30 个 | 5,000-12,000 | 3.9%-9.4% |
当智能体同时连接 3-5 个 MCP Server 时,仅工具定义就可能占据上下文窗口的 5%-15%。这些 token 从会话开始就被占用,无论用户是否真的需要调用这些工具。
上下文窗口是智能体最稀缺的资源。每个 token 位置都有机会成本——用于加载工具定义的 token,就不能用于承载用户指令、历史对话或分析结果。上下文空间的分配本质上是一个资源配置问题。
这个问题在实际使用中会进一步放大。假设一个金融分析场景需要连接行情数据、新闻检索、财务报表三个 MCP Server,工具定义可能消耗 8,000-15,000 tokens。而用户当前的需求可能只是让智能体根据已有数据写一份分析摘要——根本不需要调用任何工具。
8.1.3 从工具到技能的演化
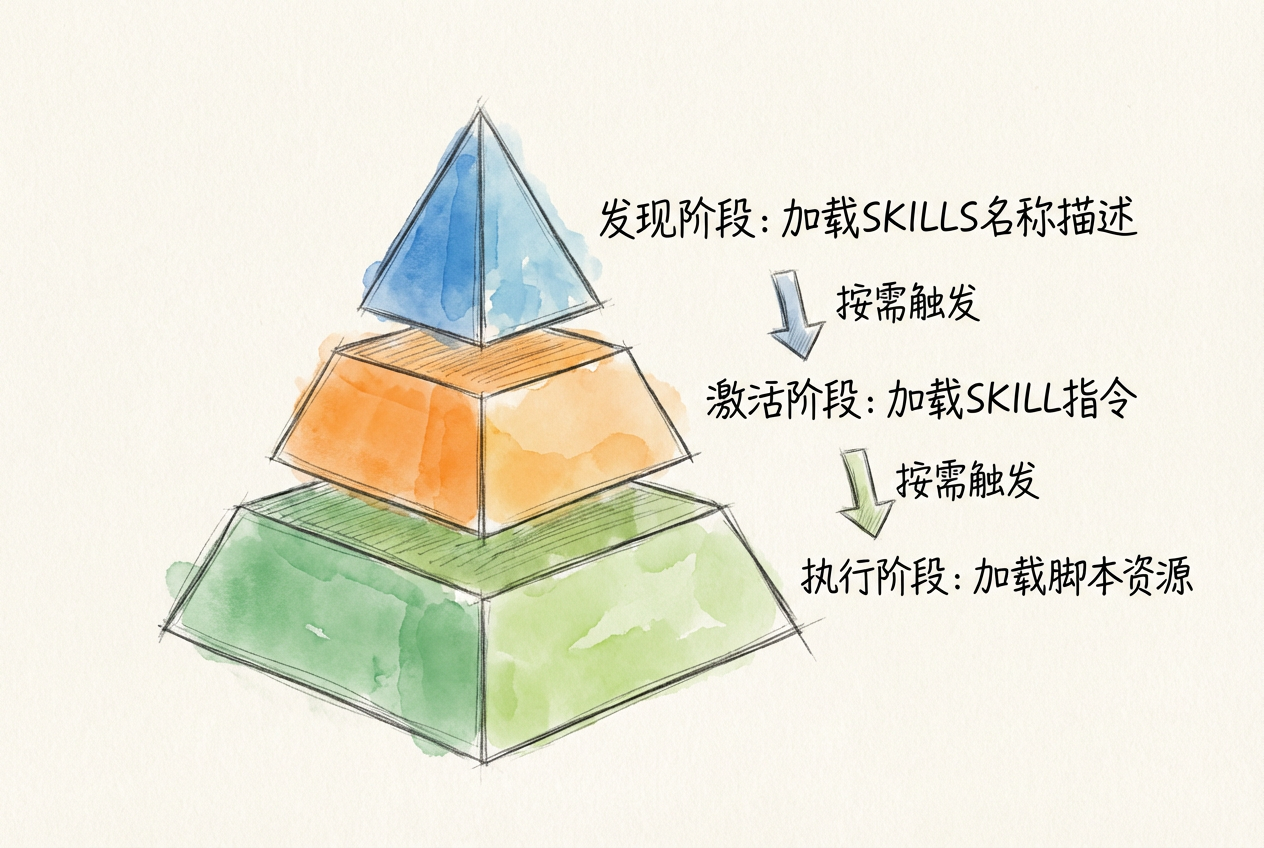
Agent Skills 的设计正是为了解决上下文效率问题。其核心思路是渐进式披露(Progressive Disclosure):不在启动时加载全部内容,而是分层按需加载。
Skills 采用三层加载架构:
| 层级 | 加载时机 | 加载内容 | Token 消耗 |
|---|---|---|---|
| 第 1 层 | 智能体启动时 | 仅 name 和 description | 约 100 tokens/skill |
| 第 2 层 | 智能体判断相关时 | 完整 SKILL.md 指令文本 | 建议 < 5,000 tokens |
| 第 3 层 | 执行过程中按需 | scripts/、references/、assets/ | 视内容而定 |
对比同样功能的 MCP 工具和 Skill 的上下文消耗差异:
假设一个智能体配置了 10 个 MCP 工具和 10 个 Skills。
- MCP 方式:启动即加载全部工具定义,消耗约 3,000-5,000 tokens。
- Skills 方式:启动仅加载名称和描述,消耗约 1,000 tokens。实际激活 2-3 个 Skill 时,再加载对应指令,额外消耗 5,000-10,000 tokens。但未激活的 7-8 个 Skill 不产生任何额外消耗。
渐进式披露是用户界面设计中的经典原则,指系统只在用户需要时才展示详细信息。搜索引擎的结果摘要就是典型应用——先展示标题和摘要,用户点击后才加载完整网页。Skills 将同样的原则应用于智能体的上下文管理。
8.1.4 Agent Skills 的定义与技术本质
Agent Skills 是包含指令、脚本和资源的标准化文件夹。智能体在运行时通过文件系统发现这些文件夹,并根据用户请求按需加载其中的内容。
一个 Skill 的标准目录结构如下:
my-skill/
├── SKILL.md # 指令文件(必需):定义 Skill 的行为规则
├── scripts/ # 脚本目录(可选):可执行的脚本文件
│ └── run.py
├── references/ # 参考资料(可选):补充文档或数据
│ └── template.txt
└── assets/ # 资源文件(可选):图片、配置等
└── config.json其中 SKILL.md 是唯一必需的文件。它用自然语言描述这个 Skill 做什么、怎么做、在什么条件下触发。智能体读取这个文件后,就获得了执行该任务的完整知识。
技术本质:提示注入而非函数调用。
这是 Skills 与 MCP 工具最根本的区别。当一个 MCP 工具被调用时,模型生成结构化参数,系统执行函数并返回结果。整个过程有明确的输入输出接口。
而当一个 Skill 被激活时,SKILL.md 的内容被注入到当前对话上下文中。没有 API 接口,没有参数传递,没有返回值。Skill 改变的是智能体的行为方式和知识储备,而不是让它执行一个具体操作。
MCP 工具调用 Skill 激活
┌──────────────────┐ ┌──────────────────┐
用户请求 → │ 模型生成参数 │ 用户请求 → │ 模型判断相关性 │
│ 系统执行函数 │ │ 系统加载 SKILL.md │
│ 返回结构化结果 │ │ 注入对话上下文 │
└──────────────────┘ │ 模型按指令行动 │
有明确的 I/O 接口 └──────────────────┘
无 I/O 接口,
改变行为方式可以这样区分两者的作用:MCP 工具给智能体增加了能力(ability),Skill 给智能体增加了知识(knowledge)。能力是执行动作的接口,知识是指导行为的规则。
Skill 的匹配和激活完全依赖大语言模型的推理能力。当用户发出请求时,模型将请求内容与已加载的 Skill 名称和描述进行语义比对,判断哪个 Skill 与当前任务相关。这个过程没有嵌入向量检索,没有分类器,是纯 LLM 推理。
8.1.5 Skills 与 MCP 的互补关系
Skills 和 MCP 不是替代关系,而是互补关系。两者解决不同层面的问题,在完整的智能体系统中各有分工。
| 维度 | Agent Skills | MCP |
|---|---|---|
| 技术本质 | 静态知识和指令(文件) | 实时工具访问(运行中的服务) |
| 编码内容 | 程序性知识:做什么、怎么做 | 数据接口:从哪里获取、何时调用 |
| 加载方式 | 文件系统发现,按需读取 | 服务器连接,全量推送 |
| 上下文策略 | 渐进式披露,分层加载 | 启动时全量加载 |
| 适用场景 | 工作流编排、分析框架、报告模板 | 实时数据查询、API 调用、系统操作 |
| 运行依赖 | 无外部依赖,纯文件 | 需要运行中的 MCP Server |
以一个金融研报生成任务为例,两者的协作方式如下:
- MCP 负责数据获取:连接行情 MCP Server 拉取最新股价,连接财务数据 MCP Server 获取季度报表,连接新闻 MCP Server 检索相关资讯。
- Skills 负责分析流程:加载研报写作 Skill,其中定义了研报的标准结构、分析框架、评级标准和输出格式。
MCP 回答的是数据从哪里来,Skills 回答的是拿到数据后怎么处理。
智能体的完整能力栈 = MCP(数据访问层) + Skills(知识与流程层) + 模型推理(决策层)。三者各司其职,缺一不可。
8.1.6 本章结构预览
后续各节将深入展开:
- 8.2 节:Skills 核心机制——SKILL.md 文件规范、发现-激活-执行三阶段、匹配机制与 Token 预算管理。
- 8.3 节:元技能——skill-creator 和 mcp-builder 如何创造新技能,实现 Skills 系统的自举。
- 8.4 节:Skills 使用实践——创建自定义 Skill、安装社区 Skills、调用方式与调试优化。
- 8.5 节:Skills 生态与社区资源——开放标准、跨平台采纳、官方仓库与社区平台。
从工具调用到技能系统的演化,反映了智能体架构设计中一个更深层的趋势:从关注单次调用的准确性,转向关注整体上下文资源的高效利用。这也是上下文工程(Context Engineering)在智能体设计中的具体体现。