9.6 文档处理与检索优化
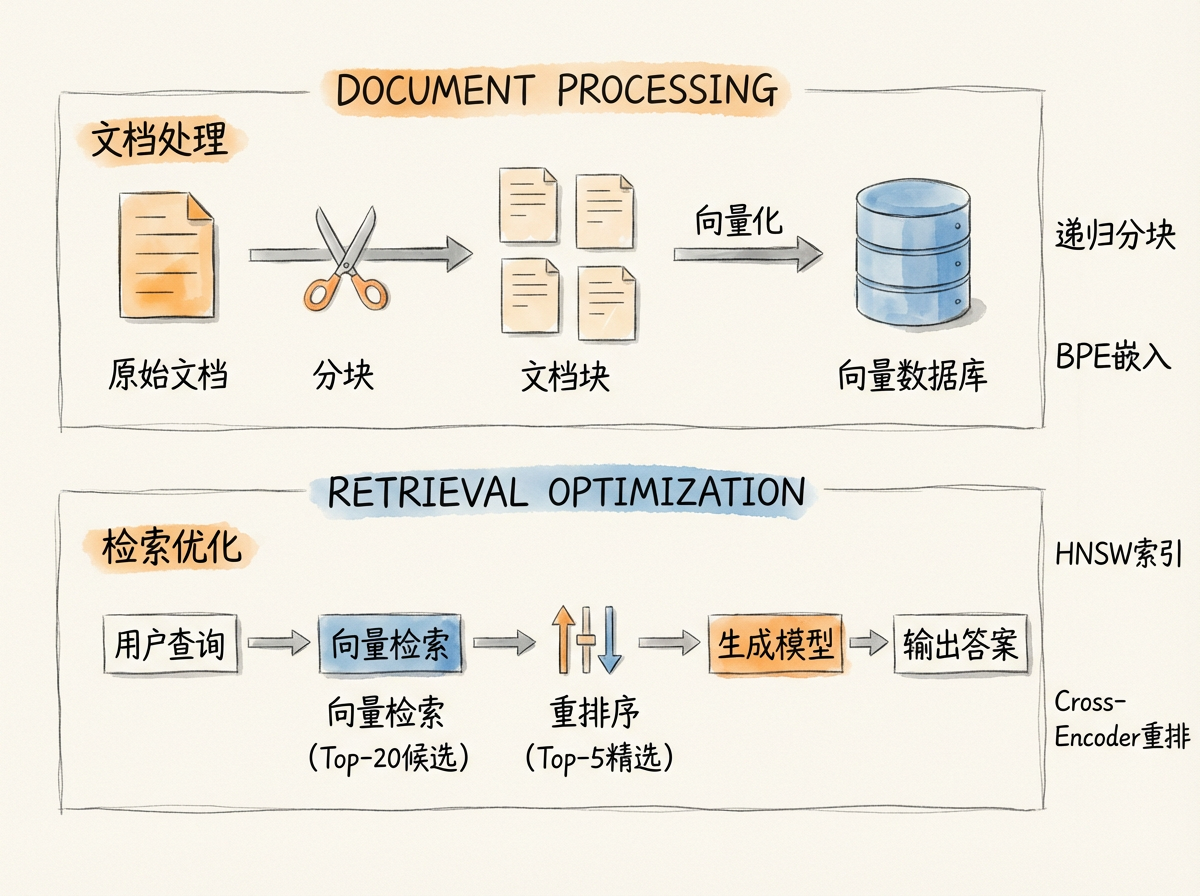
前面几节介绍了 RAG 系统的基本架构、嵌入原理和向量数据库。本节深入探讨文档分块的理论基础、分块策略、检索优化方法,以及金融文档的特殊处理。
9.6.1 文档分块的理论基础
为什么需要分块
大语言模型有上下文窗口限制。即便 Claude 的窗口达到 200K tokens,一次对话也无法容纳几十份完整的研报或政策文件。分块的首要目的是让文档适配这一物理限制。
但分块还有更深层的原因:语义稀释问题(Semantic Dilution)。
当一段文本过长时,嵌入模型生成的向量只能捕捉文本的平均语义。假设一份 5000 字的央行报告同时讨论了降准、LPR 调整、跨境资本流动三个话题,其向量就会是这三个话题的混合体。用户问「LPR 是多少」时,这份文档的语义匹配度会被其他两个话题稀释,检索排名可能不如一篇只讨论 LPR 的短文。
分块的本质是提高语义密度。每个分块聚焦一个相对单一的主题,向量才能精准表达该主题的含义。
分块粒度的权衡
分块大小是一个经典的权衡问题:
| 分块太小 | 分块太大 |
|---|---|
| 语义不完整,信息碎片化 | 语义被稀释,检索精度下降 |
| 丢失上下文,答案不连贯 | 无关内容多,增加噪声 |
| 检索到的块需要拼凑 | 单块信息冗余,浪费上下文 |
9.6.2 分块策略详解
固定长度分块
最简单的分块方式:按固定字数切分,如每 500 字一块。
优点: - 实现简单,代码量少 - 分块大小可控,便于资源规划 - 适合格式统一的文档
缺点: - 切分位置随机,可能切断句子或段落 - 不考虑文档的逻辑结构 - 语义边界与物理边界不对齐
递归分块(Recursive Chunking)
递归分块按分隔符的优先级逐层切分:
第 1 层:章节标题(# ## ###)
第 2 层:段落分隔(空行)
第 3 层:句号、问号、感叹号
第 4 层:逗号、分号
第 5 层:空格
第 6 层:字符级切分(兜底)这种方法的优势在于尊重文档的自然结构。一份结构清晰的研报会被切成「执行摘要」「行业分析」「财务分析」等自然段落,而非被机械地每 500 字一刀。
语义分块(Semantic Chunking)
语义分块更加智能:先将文档拆成句子,为每个句子生成向量,然后计算相邻句子的语义相似度。当相似度突然下降时,说明话题发生转换,此处就是语义边界。
语义分块的优势是完全按内容的逻辑边界切分。劣势是计算成本高——每个句子都需要调用嵌入模型。
分块策略选择指南
| 文档类型 | 推荐策略 | 理由 |
|---|---|---|
| 结构化报告(有章节目录) | 递归分块 | 尊重已有结构 |
| 新闻资讯 | 固定长度 | 结构简单,段落短 |
| 学术论文 | 语义分块 | 逻辑严密,话题转换明确 |
| 法规条款 | 按条款切分 | 保持条款完整性 |
| 财务报表 | 按表格切分 | 表格不可拆分 |
重叠(Overlap)的作用
重叠是指相邻分块之间共享一部分内容。关键信息可能恰好出现在分块边界。若无重叠,边界处的句子可能被切断,或与前后文脱节。重叠确保边界附近的信息在至少两个分块中完整出现,降低信息丢失的风险。
重叠率的经验值:
| 场景 | 推荐重叠率 | 说明 |
|---|---|---|
| 通用文档 | 10%-15% | 平衡存储与覆盖 |
| 金融报告 | 15% | 保留数据上下文 |
| 技术文档 | 20%-30% | 逻辑链较长 |
| 新闻短讯 | 5%-10% | 段落独立性强 |
9.6.3 检索优化方法
分块存入向量数据库后,检索阶段的优化直接决定 RAG 系统的最终效果。
重排序(Reranking)
初步向量检索速度快但精度有限。重排序(Reranking)用更精确的模型对初步结果进行二次排序。
- 初步检索使用双编码器(Bi-Encoder):问题和文档分别编码成向量,比较相似度。速度快(毫秒级),但问题和文档没有交互,无法捕捉细粒度的语义匹配。
- 重排序使用交叉编码器(Cross-Encoder):把问题和文档拼接在一起,让模型同时处理两段文字,输出一个相关性分数。精度高,但速度慢(几百毫秒一对)。
生产环境的标准流程:
- 向量检索 Top-20(毫秒级)
- 交叉编码器重排至 Top-5(几百毫秒)
- 将 Top-5 送入生成模型
重排序对最终效果的提升通常在 20%-35% 之间。
混合检索(Hybrid Retrieval)
向量检索擅长语义匹配:「降准」能检索到「下调存款准备金率」。但它对精确关键词匹配较弱:搜索文件编号「银发〔2024〕187 号」,可能返回一堆「银行文件」相关的内容,却漏掉精确匹配的文档。
关键词检索(如 BM25 算法)则擅长精确匹配,但不理解语义。
混合检索将两者结合:
最终得分 = α × 向量相似度 + (1-α) × BM25 得分不同场景的推荐权重:
| 场景 | 向量权重 (α) | BM25 权重 | 说明 |
|---|---|---|---|
| 概念解释类查询 | 0.7 | 0.3 | 语义理解为主 |
| 法规政策查询 | 0.4 | 0.6 | 精确匹配更重要 |
| 跨语言查询 | 0.8 | 0.2 | 向量跨语言能力强 |
| 数据查询 | 0.3 | 0.7 | 数字、日期需精确匹配 |
查询改写(Query Rewriting)
用户的提问方式往往与文档的表述不一致。查询改写通过生成多个等价表述来扩大检索覆盖面。
原始查询:降息对股市有啥影响?
改写版本:
1. 利率下调对股票市场的影响
2. 货币政策宽松与权益市场表现
3. LPR 下调后 A 股走势分析HyDE(Hypothetical Document Embeddings)
HyDE 是一种反直觉但有效的技术:先让模型生成一个假设性答案,然后用这个假设答案的向量去检索。
为什么有效?知识库中存储的都是陈述性内容(答案),而用户的查询是疑问句。两者的语义形式不同,向量匹配度受限。用答案去搜索答案,形式更一致,匹配度更高。
9.6.4 检索质量评估
召回率(Recall@K)
定义:在 Top-K 个检索结果中,包含正确答案的查询占总查询数的比例。
目标值:Recall@5 > 80%,Recall@10 > 90%。
平均倒数排名(Mean Reciprocal Rank,MRR)
MRR 衡量正确答案出现的位置。正确答案排在第 1 位时倒数排名为 1,排在第 2 位时为 0.5,排在第 5 位时为 0.2。
目标值:MRR > 0.6。
评估与优化的迭代过程
检索优化是一个迭代过程:
- 建立基线:用当前策略在测试集上计算 Recall@K 和 MRR
- 识别问题:找出检索失败的案例,分析原因
- 调整参数:修改分块大小、重叠率、检索参数
- 重新评估:在同一测试集上计算新指标
- 对比改进:若指标提升,保留修改;否则回退
9.6.5 金融文档的特殊考量
表格数据的处理
资产负债表、利润表、现金流量表等财务表格是金融文档的核心内容。表格切分会破坏数据的行列关系,导致信息丧失。
处理原则: 1. 整表存储:将整张表格作为一个独立分块,不切分 2. 添加表头摘要:在向量中存储表头和关键数据的文字描述 3. 表格 + 解读配对:将表格与其下方的分析文字绑定存储
财务数据的上下文保留
财务比率和增长数据必须保留其参照基准。「净利润率为 15%」单独看不知道是什么业务的净利润率。
处理方法: 1. 扩大分块窗口,确保数据与其描述在同一块中 2. 使用语义分块,保持分析段落的完整性 3. 为数据块添加元数据标签
政策文件的结构化分块
央行报告、监管政策通常有清晰的章节结构。利用这些结构作为天然的分块边界,比固定字数切分效果更好。递归分块策略特别适合此类文档。
时效性标记
金融信息有强时效性。建议: 1. 为每个分块添加时间元数据(发布日期、有效期) 2. 检索时支持时间过滤 3. 对过期文档标记提示,避免引用已失效的信息
金融领域对信息准确性要求极高。即使 RAG 系统给出了答案和来源,关键决策前仍需人工核查原文。RAG 是辅助工具,不能替代专业判断。