9.1 RAG 系统概述
检索增强生成(Retrieval-Augmented Generation,RAG)是当前大语言模型应用中最重要的架构范式之一。本节从理论层面剖析 RAG 的核心机制、与传统方法的区别,以及其在金融领域的独特价值。
9.1.1 RAG 的定义与动机
定义
RAG 是一种将信息检索与文本生成相结合的技术架构。其核心思想是:在大语言模型生成回答之前,先从外部知识库中检索相关信息,将检索结果作为上下文输入模型,从而生成更准确、更有依据的回答。
大语言模型的知识局限性
大语言模型的知识来源于训练数据。这一特性带来两个根本性限制:
第一,知识截止问题(Knowledge Cutoff)。模型的知识停留在训练数据的截止日期。对于金融领域而言,2024 年训练的模型无法了解 2025 年的货币政策调整、最新的监管规定或市场动态。当用户询问「最新的 LPR 报价是多少」时,模型只能给出过时的数据。
第二,幻觉问题(Hallucination)。当模型缺乏某一领域的知识时,它往往不会承认不知道,而是生成看似合理但实际错误的内容。在金融场景中,这种幻觉尤其危险——一个错误的政策解读或数据引用可能导致投资决策失误或合规风险。
幻觉(Hallucination)指大语言模型生成与事实不符的内容,但表述方式却自信流畅。幻觉产生的根源在于模型本质上是一个概率预测系统——它预测下一个最可能出现的词,而非检索已知事实。
RAG 如何解决这些问题
RAG 通过引入外部知识库,从根本上改变了模型的回答机制:
| 传统模式 | RAG 模式 |
|---|---|
| 完全依赖模型内部参数存储的知识 | 实时检索外部知识库 |
| 知识固定在训练时刻 | 知识库可随时更新 |
| 无法追溯信息来源 | 可标注每个回答的文档依据 |
| 对领域知识覆盖不均 | 可针对特定领域构建专属知识库 |
对于金融应用而言,RAG 的价值尤为突出。金融信息具有高度时效性——央行政策、市场行情、监管规定每天都在变化。同时,金融行业对信息准确性有严格要求,任何数据引用都需要可追溯、可验证。RAG 恰好满足这两项核心需求。
9.1.2 RAG 的三阶段架构
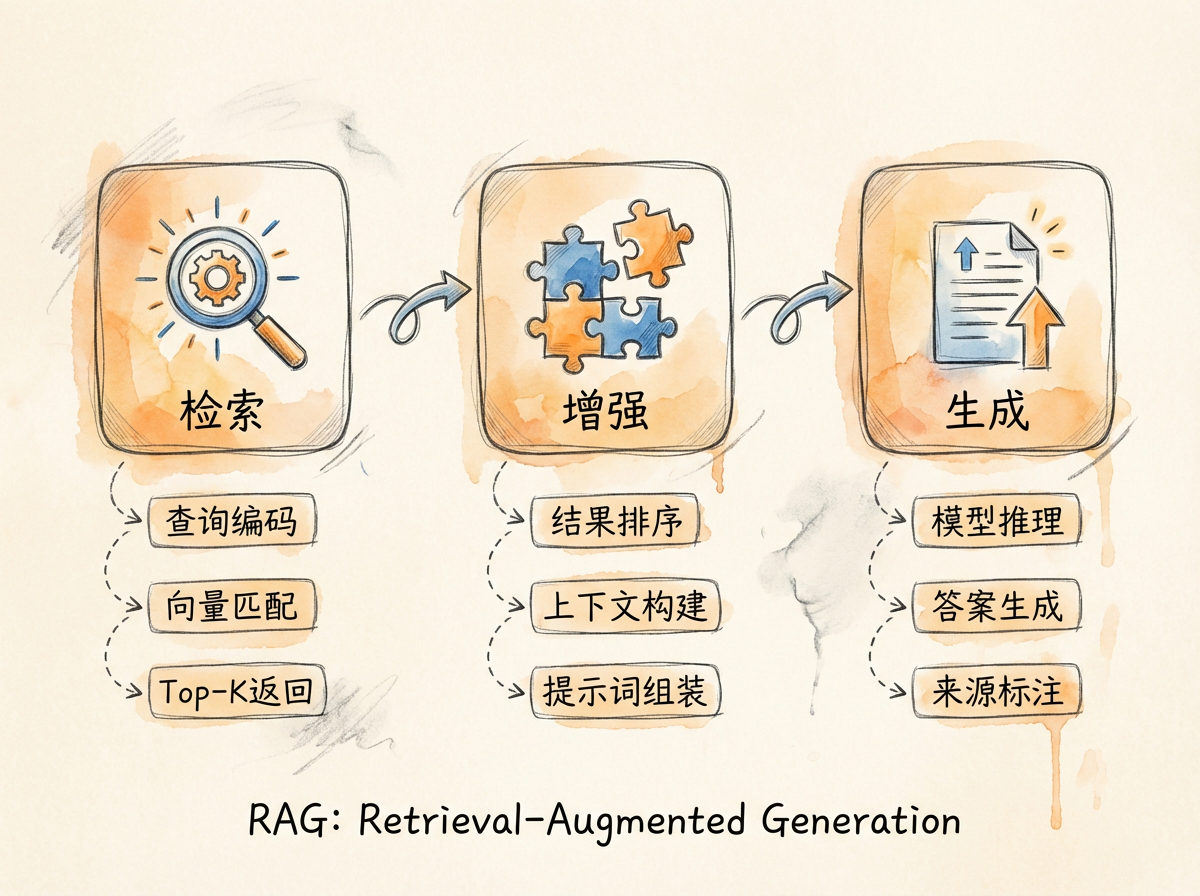
RAG 系统的工作流程可分为三个阶段:检索(Retrieval)、增强(Augmentation)、生成(Generation)。
第一阶段:检索
检索阶段的任务是从外部知识库中找出与用户查询最相关的文档片段。
这一阶段涉及两个核心技术:
查询编码:将用户的自然语言问题转换为向量表示(Vector Representation),这一过程由嵌入模型(Embedding Model)完成。
相似度匹配:在向量数据库中搜索与查询向量最相似的文档向量,返回 Top-K 个最相关的文档片段。
检索质量直接决定了整个系统的上限。如果这一阶段无法找到正确的信息源,后续的生成阶段再优秀也无济于事。
第二阶段:增强
增强阶段的任务是将检索到的文档片段与用户的原始问题整合为一个结构化的提示词(Prompt)。
这一阶段的关键在于上下文构建策略:
- 如何排列多个检索结果的顺序
- 是否需要对检索内容进行摘要或压缩
- 如何在提示词中明确指示模型使用检索内容
一个典型的增强后提示词结构如下:
系统指令:请基于以下参考资料回答用户问题。如果资料中没有相关信息,请明确告知。
参考资料:
[文档片段 1]
[文档片段 2]
[文档片段 3]
用户问题:{用户的原始问题}第三阶段:生成
生成阶段由大语言模型完成。模型接收增强后的提示词,基于其中的参考资料生成回答。
与普通的文本生成不同,RAG 模式下的生成具有以下特征:
- 回答应当基于检索到的文档内容,而非模型的内部知识
- 回答中应标注信息来源,便于用户验证
- 当检索内容不足以回答问题时,模型应承认信息不足
RAG 的三阶段层层递进:检索阶段决定信息源的质量,增强阶段决定上下文的组织方式,生成阶段决定最终回答的表达。检索准确性和增强策略共同决定了回答的品质。
9.1.3 RAG 与微调的理论对比
给大语言模型补充专业知识,存在两条技术路径:RAG 和微调(Fine-tuning)。理解两者的理论差异,有助于在实际项目中做出正确选择。
微调的原理
微调是指在预训练模型的基础上,使用特定领域的数据继续训练,从而调整模型的参数。经过微调后,领域知识被编码到模型的权重中,模型在该领域的表现会显著提升。
RAG 的原理
RAG 不修改模型参数,而是在推理时为模型提供外部知识。模型的核心能力保持不变,但通过检索增强,它可以回答训练数据中未曾覆盖的问题。
理论权衡分析
| 维度 | 微调 | RAG |
|---|---|---|
| 知识存储位置 | 模型参数(内化) | 外部数据库(外挂) |
| 知识更新成本 | 高(需重新训练) | 低(更新文档即可) |
| 计算资源需求 | 高(需 GPU 训练) | 中(需向量数据库) |
| 可追溯性 | 弱(无法标注来源) | 强(可标注文档来源) |
| 对模型的改变 | 永久改变参数 | 不改变参数 |
| 适合的知识类型 | 稳定、结构化的领域知识 | 动态、需频繁更新的信息 |
对于金融场景,推荐采用「RAG 为主、微调为辅」的混合策略:
- RAG 负责:实时政策信息、市场数据、监管规定等需要频繁更新且要求可追溯的内容
- 微调负责:金融领域的专业表达风格、特定任务(如财报摘要格式)的输出规范
对于本书的学习者而言,掌握 RAG 技术足以应对绝大多数应用场景。
9.1.4 RAG 的理论基础
RAG 技术建立在多个学科领域的理论基础之上。理解这些基础有助于把握 RAG 的本质,并在实践中做出更合理的设计决策。
信息检索传统
信息检索(Information Retrieval,IR)是计算机科学中一个历史悠久的研究领域,其核心问题是:如何从大规模文档集合中找到与用户需求相关的内容。
传统信息检索主要依赖词频统计方法。经典的 TF-IDF(词频-逆文档频率)和 BM25 算法通过统计词语在文档中出现的频率来衡量相关性。这类方法的优点是计算高效、可解释性强,缺点是无法理解语义——「降低存款准备金率」和「降准」在词汇层面毫无关联,但它们表达的是同一概念。
RAG 中的检索模块继承了信息检索领域的核心思想,但用向量语义检索替代了传统的关键词匹配,从而克服了语义鸿沟问题。
语义匹配与表示学习
语义匹配的关键在于将文本转换为能够捕捉其含义的数学表示。这一任务由表示学习(Representation Learning)技术解决。
表示学习的核心思想是:将高维、离散的符号(如文字)映射到低维、连续的向量空间。在这个空间中,语义相近的文本对应的向量位置也相近。
向量嵌入模型(Embedding Model)是实现这一映射的工具。它接收一段文本作为输入,输出一个固定长度的浮点数向量(如 1024 维)。这个向量可以理解为文本在语义空间中的坐标。
向量嵌入的理论根源可追溯到分布式语义假说(Distributional Semantics Hypothesis):语义相似的词语倾向于出现在相似的上下文中。现代嵌入模型通过在大规模语料上训练神经网络,学习到了这种上下文分布规律,从而能够将语义信息编码为向量。
知识增强生成范式
RAG 代表了一种新的生成范式:知识增强生成(Knowledge-Augmented Generation)。与纯粹依赖模型内部参数的生成方式不同,这一范式将外部知识显式地引入生成过程。
这一范式具有以下理论优势:
知识与推理的分离:模型负责推理和生成,知识库负责存储事实。这种分离使得两者可以独立优化和更新。
可扩展性:知识库的规模可以任意扩展,而不需要增加模型的参数量。这解决了将所有知识塞入模型参数的根本性局限。
可验证性:生成的内容可以追溯到具体的知识条目,便于人工审核和错误排查。
9.1.5 RAG 在金融领域的应用价值
金融行业的三个显著特征,使其成为 RAG 技术的天然应用场景。
信息密集性
金融从业者每天面对海量文档:财务报表、研究报告、政策文件、市场公告、新闻资讯。传统的信息获取方式依赖人工搜索和阅读,效率低下且容易遗漏关键信息。
RAG 系统可以将这些文档纳入知识库,支持自然语言查询。分析师可以用日常语言提问,系统自动从数万份文档中检索相关内容。这大幅提升了信息获取效率。
高时效性要求
金融市场的信息窗口极短。央行今天发布的政策,明天就需要反映在投资决策中。监管规定的变化可能即时影响业务合规性。
RAG 的增量更新特性正好满足这一需求。新文档可以在发布后立即索引入库,无需重新训练模型。上午发布的政策,下午就可以被检索和引用。
合规与审计要求
金融行业受到严格的监管。投资建议、风险评估、合规判断都需要有据可查。如果 AI 系统给出一个结论,审计人员需要能够验证这个结论的依据是什么。
RAG 的来源标注机制直接满足了这一要求。每个回答都可以附带其引用的文档来源、具体段落,甚至原文引述。这种可追溯性是纯粹依赖模型内部知识的系统无法提供的。
典型应用场景
| 应用场景 | RAG 的价值 |
|---|---|
| 政策文档问答 | 自然语言查询央行报告、监管规定,秒级返回相关条款 |
| 投研报告辅助 | 自动检索财报数据、行业信息,为分析师提供素材 |
| 智能客服 | 从产品说明书、FAQ 中检索信息,准确回答客户咨询 |
| 合规审查 | 检索历史案例和法规条款,辅助判断合规性 |
| 舆情分析 | 从新闻库中检索相关报道,支撑舆情判断 |