记忆管理概述
想象一位资深理财顾问与客户的对话。客户张先生走进办公室,顾问立刻说:您上次提到计划三年内买房,最近房价有所松动,要不要聊聊购房首付的配置?这位顾问之所以能提供如此贴心的服务,关键在于他记住了客户的核心需求。
智能体也面临同样的挑战。没有记忆的智能体,每次对话都是从零开始——它不记得你上周问过什么,也不知道你偏好稳健还是激进的投资风格。这样的智能体只能充当一次性的问答工具,无法成为真正的知识伙伴。
本节我们将从认知科学出发,理解人类记忆的工作原理,建立智能体记忆系统的整体框架,并引入上下文工程这一新范式。
6.1.1 为什么智能体需要记忆
在金融服务场景中,记忆能力直接决定了智能体的服务质量。
场景一:无记忆的客服困境
第一天: - 客户:我想了解债券基金和股票基金的区别。 - 智能体:[详细解释两类基金的风险收益特征]
第二天: - 客户:那个收益稳定的基金叫什么来着? - 智能体:请问您指的是哪种基金? - 客户(不耐烦):就昨天聊的那个啊! - 智能体:对不起,我没有昨天的对话记录…
第三天: - 客户:我考虑清楚了,就买那个稳健的。 - 智能体:您好,请问需要购买什么产品? - 客户:[关闭对话]
这种体验令人沮丧。客户不得不重复说明自己的需求,交流效率大打折扣。
场景二:有记忆的智能顾问
同样的客户第二天继续咨询:
智能体主动提示:您昨天询问了债券基金,它的特点是收益相对稳定、波动较小。您的风险偏好是保守型,建议关注中短期纯债基金。需要我推荐几只具体产品吗?
这才是有价值的金融服务。记忆让智能体从一次性工具进化为持续服务的知识伙伴。
记忆能力的商业价值体现在三个维度:
- 客户留存率:记住偏好的智能体能提供个性化服务,客户黏性更强
- 服务连续性:跨会话保持知识积累,避免重复沟通
- 决策一致性:基于历史经验做出稳定判断,而非每次从零开始
6.1.2 记忆的认知科学基础
要设计智能体的记忆系统,我们先看看人类大脑是如何管理记忆的。认知神经科学研究揭示,人类记忆系统存在多个层次,各层次分工明确、协同工作。
感觉记忆
这是信息进入大脑的第一站。当你看一眼股票报价屏,所有数字都会短暂停留在视觉系统中——但仅仅持续几百毫秒。绝大多数信息在这个阶段就被遗忘,只有你注意到的内容才会进入下一层。
短期记忆
你刚听到的电话号码、刚看到的验证码,都存储在短期记忆中。它的容量有限,心理学经典研究表明,人类短期记忆大约只能容纳 7±2 个信息单元。更重要的是,这些信息很快就会消失——如果不加复述,几十秒后你就忘了刚才的验证码。
工作记忆
工作记忆负责信息的临时存储与主动加工。当你心算 23×17 时,你需要同时记住 23、17、中间结果 21(7×3)、161(7×23)等数字,并按照乘法规则进行运算。这个过程就发生在工作记忆中。
工作记忆与短期记忆的本质区别:短期记忆只负责存储,而工作记忆不仅存储,还能主动加工——它可以调用长期记忆中的知识,进行逻辑分析和推理。
心理学家 Baddeley 提出的工作记忆模型包含三个子系统:语音环路(处理语言信息)、视空间画板(处理图像信息)、中央执行系统(协调整合)。这个模型对智能体设计有重要启发。
长期记忆
你的母语词汇、骑自行车的技能、童年的重要经历——这些都存储在长期记忆中。它的容量几乎无限,保存时间可达数十年。但长期记忆的写入需要时间和重复,检索也可能失败(想想那些话到嘴边却想不起来的时刻)。
6.1.3 智能体记忆的四层架构
借鉴人类记忆系统的分层设计,智能体的记忆架构也可以分为四个层次。
| 人类记忆 | 智能体对应 | 持续时间 | 容量 | 典型内容 |
|---|---|---|---|---|
| 工作记忆 | 上下文窗口 | 任务期间 | 200K tokens | 当前任务描述、系统提示、相关文档摘要、工具输出 |
| 短期记忆 | 会话历史 | 会话期间 | 会话级 | 完整问答对、中间推理过程、临时变量 |
| 长期记忆 | 外部存储 | 持久 | 无限 | 用户画像、知识库、项目配置、历史报告 |
| 情景记忆 | 决策日志 | 选择性持久 | 按需 | 决策轨迹、市场情境标签、经验教训、反思记录 |
工作记忆:上下文窗口
智能体处理任务时,需要把相关信息加载到上下文窗口中。上下文窗口的大小决定了智能体能同时处理多少信息——Claude Sonnet 4 的上下文窗口是 200K tokens。
但窗口容量有限。当信息太多时,必须移除一部分内容,为新信息腾出空间。因此,上下文管理是记忆系统的核心技能。
短期记忆:会话历史
从对话开始到结束,所有的问答记录都保存在短期记忆中。它保证了对话的连贯性:当客户说”就选这个”时,智能体知道”这个”指的是刚才讨论的那只基金。
长期记忆:跨会话持久化
会话结束后,重要信息需要保存到外部存储(文件、数据库)。下次客户再来咨询时,智能体可以检索这些记忆,接续之前的服务。
情景记忆:决策轨迹
这是一种特殊的长期记忆,存储的不是知识,而是经历。比如,智能体记录了这样一条经历:2024 年 8 月 15 日,客户想在科技股大涨时追高买入,我建议分批建仓,客户采纳后平均成本降低 2.5%。当类似情况再次出现时,智能体可以借鉴这段经验。
6.1.4 上下文工程:从存储到检索的范式转变
传统的记忆管理思维是追求存储更多——更大的上下文窗口、更多的存储空间。但这种思路存在根本性缺陷。
传统思维:如何存储更多信息?
新范式:如何在正确的时间检索正确的信息?
核心洞见:记忆的价值在于检索,而非存储。
为什么更大的窗口不能解决问题
直觉上,我们以为更大的上下文窗口意味着更好的记忆。但研究表明并非如此:
- 注意力稀释:窗口越大,每个位置分到的注意力越少
- 训练分布偏移:模型训练时短序列占主导,长序列经验不足
- 成本不成比例增长:双倍 tokens 带来的可能是超过双倍的成本和延迟
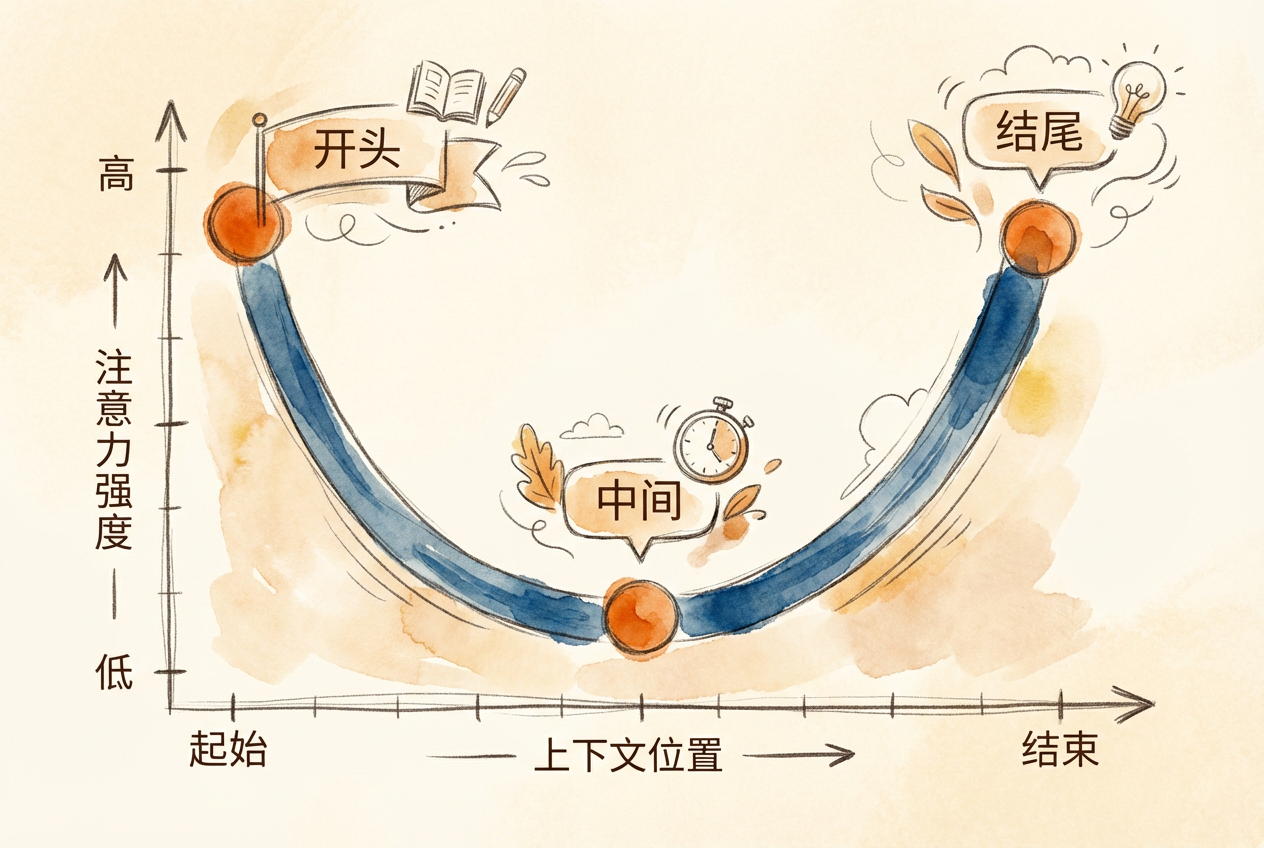
研究发现,Transformer 模型的注意力分布呈 U 型曲线:开头和结尾的信息召回率最高,中间区域下降 10-40%。这意味着关键信息应放在系统提示(开头)和当前任务描述(结尾),而非中间位置。
RULER 基准测试发现:声称支持 32K+ tokens 上下文的模型中,只有 50% 能在 32K 时保持满意性能。
约束优化框架
上下文工程是一个优化问题:
- 目标函数:最大化输出质量
- 约束条件:令牌预算、延迟要求、成本限制、注意力容量
- 决策变量:什么信息进入上下文、放在什么位置、以什么形式
上下文窗口是具有机会成本的经济资源。把所有可能有用的信息填入上下文,等于把所有资产都变成现金持有——流动性最大化,但收益最低。
令牌分配类似于投资组合配置:在有限资源下追求最优收益。每个 token 都有成本(金钱和注意力),需要精心配置。
上下文工程的核心任务
找到最小的高信号 token 集合,最大化期望输出质量。这个定义包含两层含义:
- 最小化:不是越多越好,而是恰到好处
- 高信号:相关性和信息密度比数量更重要
这个范式转变对记忆系统设计有深远影响。在后续章节中,我们将学习如何通过压缩、缓存、分层加载等技术,实现高效的上下文管理。