10.3 智能体并行化
并行化(Parallelization)是多智能体系统提高效率的关键技术。通过将独立任务分配给多个智能体同时执行,可以显著缩短整体处理时间。在金融场景中,这种能力尤为重要,比如同时收集多个市场的数据、并行分析不同资产的表现。
10.3.1 任务分解与并行策略
将一个大任务拆分为多个独立或弱依赖的子任务,是并行化的前提。
任务分解原则
- 独立性原则:子任务之间应尽量减少数据依赖。如果任务 A 必须等待任务 B 完成才能开始,那么它们无法真正并行。
- 粒度平衡:任务不能拆得太细,否则协调开销会抵消并行带来的收益。也不能太粗,否则无法充分利用并行能力。
- 负载均衡:各个子任务的工作量应该相对均衡,避免出现部分智能体空闲而部分智能体过载的情况。
并行执行策略
扇出-收集模式
这是最常见的并行模式。主智能体将任务扇出给多个子智能体并行执行,然后收集所有结果进行汇总。
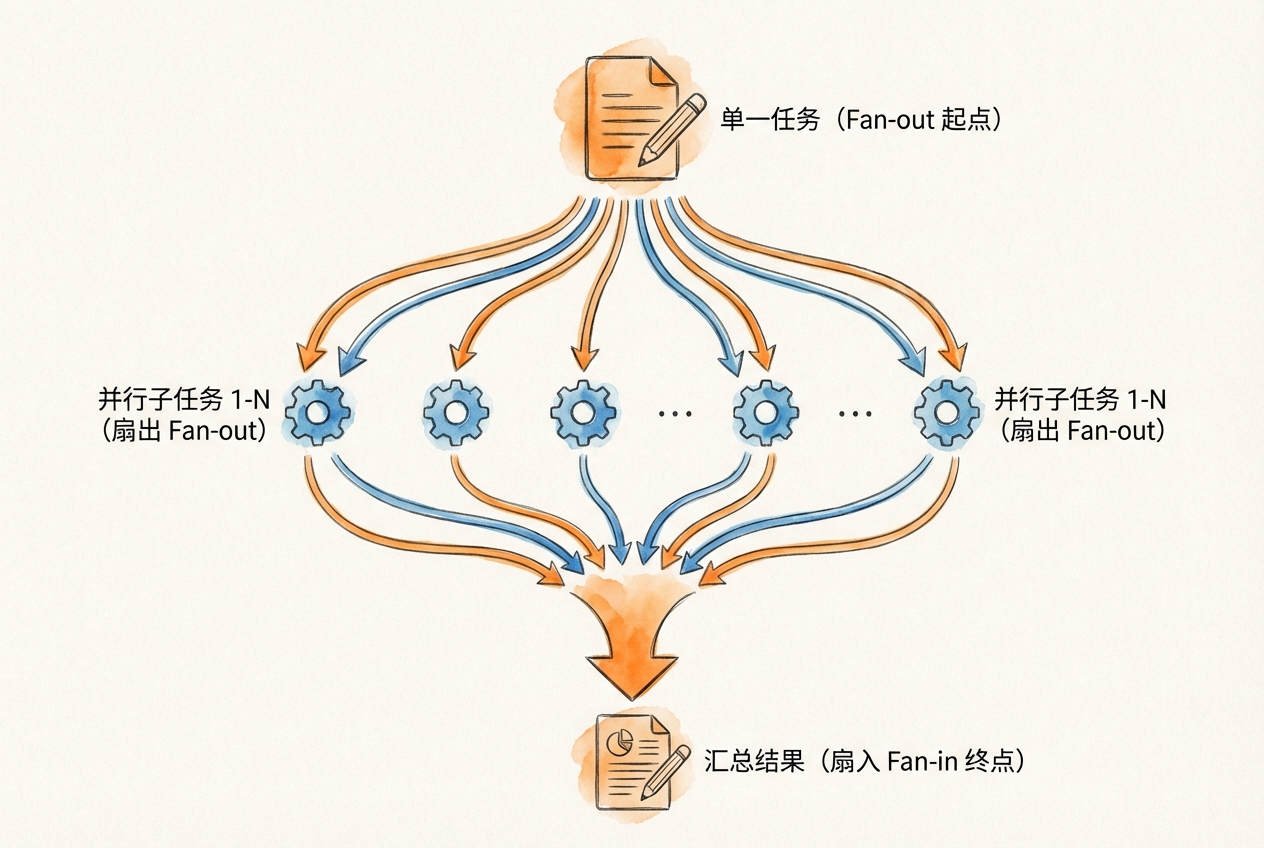
典型应用场景:多市场数据采集、多维度风险分析、多策略回测。
流水线并行
将任务分解为多个阶段,每个阶段由专门的智能体处理。虽然单个数据项要经过多个阶段,但多个数据项可以同时处于不同阶段。
数据项 1 → 阶段A → 阶段B → 阶段C → 输出
数据项 2 → 阶段A → 阶段B → 阶段C → 输出
数据项 3 → 阶段A → 阶段B → 阶段C典型应用场景:数据预处理→特征提取→模型预测的流水线处理。
数据并行
对同质化的数据集进行分片,每个智能体处理一个分片,最后合并结果。这种模式与 MapReduce 思想一致。
典型应用场景:大规模股票筛选、历史数据批量分析。
MapReduce 是 Google 提出的分布式计算模型。Map 阶段将任务分发给多个节点并行处理,Reduce 阶段汇总所有节点的结果。金融领域的多智能体并行化与此思想一脉相承。
10.3.2 结果聚合机制
聚合方式
简单合并:将各智能体的结果直接拼接或求和。适用于结果互不冲突的场景。
智能体1 → [股票A, 股票B]
智能体2 → [股票C, 股票D]
智能体3 → [股票E, 股票F]
↓
合并结果 = [股票A, 股票B, 股票C, 股票D, 股票E, 股票F]加权平均:根据智能体的可靠性或数据质量赋予不同权重。
智能体1 评分 85 (权重0.4)
智能体2 评分 90 (权重0.3)
智能体3 评分 75 (权重0.3)
↓
最终评分 = 85×0.4 + 90×0.3 + 75×0.3 = 83.5投票机制:对于分类或决策问题,采用多数投票或加权投票。
买入信号:智能体1, 智能体2, 智能体5
持有信号:智能体3, 智能体4
↓
最终决策 = 买入 (3票 vs 2票)时序聚合
对于有时间维度的数据,需要考虑时序一致性:
- 时间戳对齐:各智能体返回的数据可能有轻微时间差,需要对齐到统一时刻
- 增量更新:在实时场景中,各智能体持续产生增量数据,汇总智能体需要维护全局状态
10.3.3 一致性检查与冲突处理
数据一致性验证
交叉验证:如果多个智能体提供了相同维度的数据,需要检查一致性。
智能体A 报告:某股票价格 = 100.5
智能体B 报告:某股票价格 = 100.2
↓
差异 = |100.5 - 100.2| = 0.3
差异率 = 0.3/100.35 = 0.3%
↓
如果差异率 < 阈值(1%),取平均值 100.35
如果差异率 > 阈值,标记为异常需人工介入来源追溯:当检测到数据异常时,应能追溯到具体的智能体和数据来源。
冲突解决策略
- 最新优先:基于时间戳,采用最新的数据。适用于快速变化的市场数据。
- 可靠性优先:根据智能体的历史表现选择最可靠的来源。
- 人工介入:对于高风险决策,当智能体结果差异较大时,应标记并等待人工审核。
10.3.4 效率与成本权衡
并行度选择
并行智能体数量不是越多越好,需要考虑边际收益递减和协调开销。
1个智能体 → 2个智能体:时间减半,成本翻倍,性价比 = 1
2个智能体 → 4个智能体:时间再减半,成本再翻倍,性价比 = 1
4个智能体 → 8个智能体:时间减少有限(受最慢智能体制约),性价比 < 1协调开销包括:任务分发时间、结果汇总时间、冲突检测与解决时间、通信开销。
成本模型
如果每个智能体调用外部 API(如 LLM),成本会线性增加。以 Anthropic API 为例(2026 年 1 月价格):
- Haiku 模型:输入 $0.25/MTok,输出 $1.25/MTok
- Sonnet 模型:输入 $3/MTok,输出 $15/MTok
- Opus 模型:输入 $15/MTok,输出 $75/MTok
假设三个子智能体各处理 10K tokens: - 全部使用 Haiku:成本约 $0.08 - 全部使用 Sonnet:成本约 $0.90(11 倍) - 全部使用 Opus:成本约 $4.50(56 倍)
混合策略更经济:简单任务用 Haiku,复杂任务用 Sonnet,关键决策用 Opus。
不同应用场景的延迟容忍度不同:
- 实时交易决策:延迟敏感,愿意为低延迟付更高成本
- 每日报表生成:延迟不敏感,优先考虑成本优化
- 风险监控:需要平衡延迟和成本
Opencode 的 Task 工具是顺序执行的,而非真正的并行执行。 这意味着:
- 多个 Task 调用会按创建顺序依次执行
- 不会出现多个子智能体同时运行的情况
- 总执行时间仍然是各任务时间的总和,而非最大值
尽管是顺序执行,Task 工具依然有重要价值:代码组织清晰、上下文隔离、可维护性好。如果需要真正的并行,可以使用 Git Worktree 方案或外部调度系统。
| 序号 | 知识点 | 重要度 |
|---|---|---|
| 10.3.1 | 任务分解与并行策略 | ★★★ |
| 10.3.2 | 结果聚合机制 | ★★★ |
| 10.3.3 | 一致性检查与冲突处理 | ★★ |
| 10.3.4 | 并行效率与成本权衡 | ★★ |