Opencode 记忆管理实践
使用 Opencode 开发金融分析项目时,一个常见的痛点是:每次开启新会话都要从零开始建立上下文。你不得不重复告诉智能体项目是什么、偏好是什么、数据规范是什么。
Opencode 的记忆系统正是为解决这个问题而设计。它让智能体能够记住项目规范、个人偏好和工作习惯,在会话间保持连续性。
6.7.1 AGENTS.md 文件体系
AGENTS.md 是 Opencode 的长期记忆中枢。它采用分层设计,支持定义全局偏好和针对特定项目设置规范。
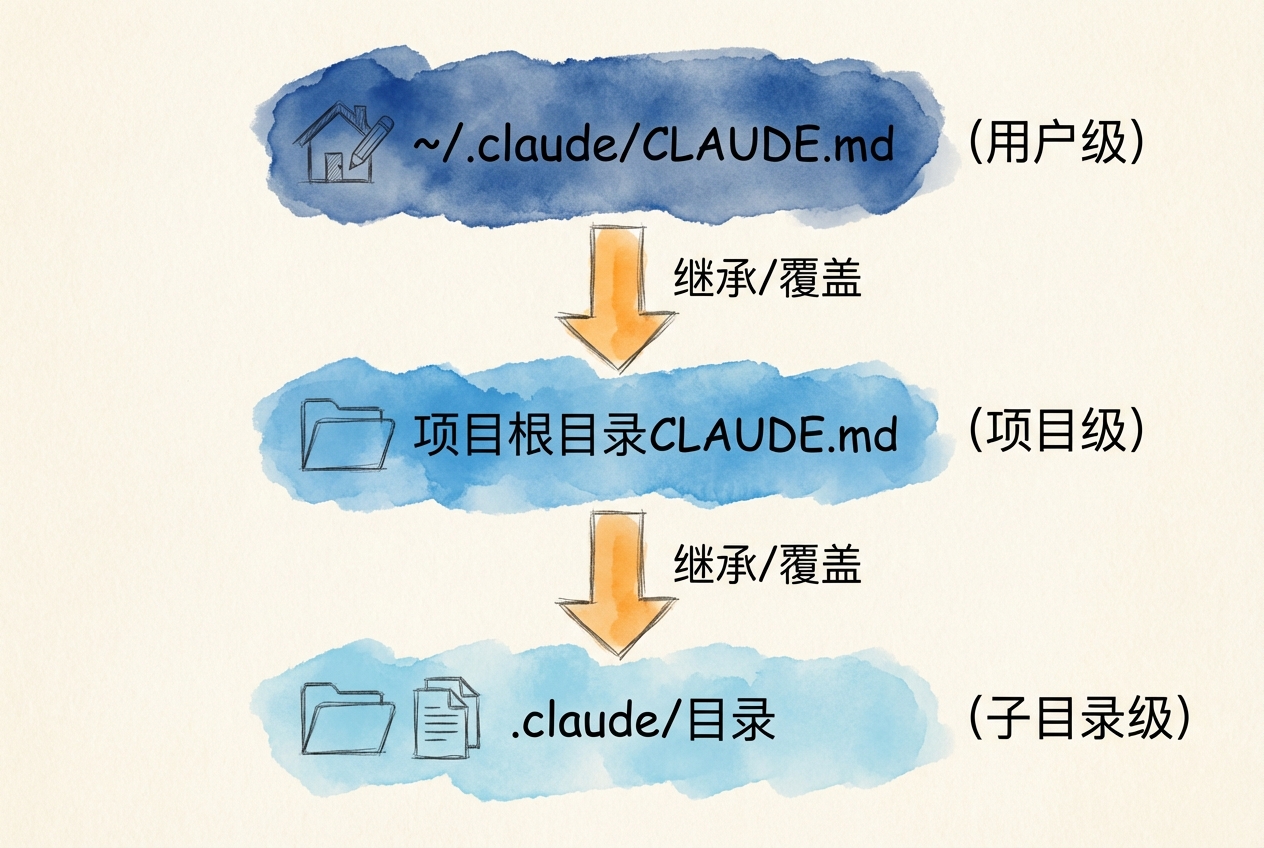
三种记忆位置
| 记忆类型 | 文件位置 | 作用范围 | 典型用途 |
|---|---|---|---|
| 用户记忆 | ~/.config/opencode/AGENTS.md |
所有项目 | 个人偏好、通用规范 |
| 项目记忆 | ./AGENTS.md |
当前项目(团队共享) | 项目架构、编码规范 |
| 子模块记忆 | ./subdir/AGENTS.md |
子目录 | 模块特定约定 |
加载机制
Opencode 启动时会递归查找 AGENTS.md 文件:
- 从当前工作目录开始
- 向上逐级查找直到用户主目录
- 层层叠加,形成完整上下文
AGENTS.md 本质上是系统提示(System Prompt)——它定义了智能体在这个项目中应该如何行事。因此,AGENTS.md 永远不会被压缩。即使执行 /compact,AGENTS.md 的内容也会完整保留。
导入功能
使用 @path/to/file 语法可以导入其他文件的内容:
# AGENTS.md
## 项目概述
这是一个金融数据分析平台。
## 配置导入
@config/coding_standards.md
@config/data_sources.md
@config/compliance_rules.md导入功能支持相对路径和绝对路径,最大递归深度为 5 层。
6.7.2 会话状态管理命令
Opencode 提供几个核心命令管理会话状态。理解它们的语义有助于选择正确的策略。
命令语义映射
| 命令 | 对应策略 | 语义 | 适用场景 |
|---|---|---|---|
/clear |
分区 | 会话级分区,完全清空历史 | 开始全新任务 |
/compact |
压缩 | 保留核心信息,释放空间 | 继续当前任务,上下文过长 |
/compact 指令 |
选择性压缩 | 按指令保留特定信息 | 需要精确控制保留内容 |
| 手动编辑 AGENTS.md | 编辑 | 直接修改 AGENTS.md 文件 | 更新项目规范 |
/session |
恢复 | 恢复之前的会话 | 跨天继续工作 |
/clear 命令
/clear完全清空当前对话历史,即会话级分区——开启一个全新的工作空间。
适用于: - 开始完全不相关的新任务 - 切换到不同项目 - 对话上下文已混乱,需要重新开始
/clear 对当前会话是破坏性的,但 AGENTS.md 文件内容会保留。如果想返回旧会话,可使用 /session 命令恢复之前的会话。
/compact 命令
/compact将当前对话压缩为更短的摘要,保留重要事实和决策。
更灵活的用法是带指令压缩:
/compact 仅保留决策和待办事项
/compact 保留所有关于估值模型的讨论
/compact 保留客户的风险偏好和投资目标这让你能精确控制保留什么信息,而不是完全依赖自动判断。
/compact 的效果类似会议纪要:保留关键决策和行动项,省略具体讨论过程,用较少篇幅承载核心信息。
6.7.3 三层信息架构实践
高效的记忆管理需要区分不同类型信息的加载策略。三层信息架构(L1/L2/L3)是一种经过验证的模式。

架构设计
| 层级 | 何时加载 | 内容类型 | Token 成本 |
|---|---|---|---|
| L1 | 始终 | SKILL.md 元数据、核心约束 | ~50 tokens |
| L2 | 按需 | MODULE.md 指令、API 规范 | ~60-80 tokens |
| L3 | 即时 | .jsonl/.yaml 具体数据 | 可变 |
L1 层(元数据):始终加载
# L1: 项目元数据(始终加载)
项目: 金融分析系统
技术: Python 3.10+, yfinance
约束: 输出 JSON 格式
核心规范: @config/core_rules.md这些是智能体必须知道的基本信息,无论执行什么任务都需要。
L2 层(指令):按需加载
# L2: 按需加载(在 AGENTS.md 中引用,任务相关时加载)
@config/api_specs.md # API 开发任务时加载
@config/data_processing.md # 数据处理任务时加载
@config/reporting_format.md # 报告生成任务时加载这些是特定任务需要的详细指令,不需要时不加载。
触发机制:任务相关时加载的判断逻辑包括: - 关键词匹配:用户请求中包含 API、接口等关键词时加载 api_specs.md - 模块调用:执行数据处理函数时加载 data_processing.md - 显式引用:用户直接要求按照报告格式时加载 reporting_format.md
L3 层(数据):即时加载
# L3: 即时加载(在任务中明确引用时才加载)
@data/client_profiles.jsonl # 分析特定客户时加载
@data/market_events.yaml # 分析市场事件时加载这些是具体的数据文件,只在明确需要时加载。
Token 效率
采用三层架构后: - 优化后:~650 tokens/任务 - 未优化:~5000 tokens/任务 - 节省:约 87%
计算示例:
假设一个典型金融分析任务:
| 层级 | 内容 | 优化前 | 优化后 |
|---|---|---|---|
| L1 元数据 | 项目名称、技术栈 | 50 | 50 |
| L2 指令 | 全部指令一次性加载 | 800 | 80(按需) |
| L3 数据 | 全部数据一次性加载 | 4000 | 500(即时) |
| 冗余信息 | 未清理的历史 | 150 | 20 |
| 合计 | 5000 | 650 |
节省率 = (5000 - 650) / 5000 = 87%
三层架构的核心思想是渐进式加载——先加载最少必要信息,需要更多细节时再按需获取。
6.7.4 上下文管理最佳实践
主动压缩策略
不要等到系统自动触发压缩才处理。建议采用主动压缩策略:
| 利用率 | 状态 | 建议操作 |
|---|---|---|
| 70% | 预警 | 开始考虑压缩 |
| 80% | 触发 | 执行 /compact |
| 90% | 紧急 | 立即 /compact 或 /clear |
实践建议:每 30-50 轮对话后主动执行 /compact,主动管理上下文是高效使用智能体的关键技能。
AGENTS.md 管理规范
| 规范 | 原因 |
|---|---|
| 保持在 200 行以内 | 过长会占用过多上下文窗口 |
| 使用 @import 分离配置 | 保持主文件简洁,便于维护 |
| 核心信息写进去,详细信息通过路径引用 | AGENTS.md 是索引入口而非完整存储 |
| 定期更新,删除过时内容 | 过时信息可能误导智能体 |
观察遮蔽在实践中的应用
研究发现,工具输出占据了典型工作流中 83.9% 的 tokens。这是优化的最大杠杆点。
Opencode 的 /compact 命令实际上实现了观察遮蔽策略:
观察遮蔽策略:
固定遮蔽:「前 X 行已省略」
- 研究发现:固定遮蔽可匹配 LLM 摘要的效果
- 优势:零 token 开销(vs 摘要的 5-7% 开销)
适用场景:
- 长日志输出
- 重复格式的数据
- 已处理完成的中间结果问题:智能体似乎没有读取 AGENTS.md 的内容
可能原因和解决方法: 1. 文件位置错误——确保在项目根目录或当前工作目录 2. 文件名拼写错误——必须是 AGENTS.md(大写),Opencode 也兼容 CLAUDE.md 格式 3. 导入路径错误——检查 @path/to/file 路径是否正确 4. 文件过大——控制在 200 行以内,过长会影响加载
问题:会话恢复失败
可能原因和解决方法: 1. 会话已过期——Opencode 会话有保留期限 2. 使用 /session 命令交互式选择要恢复的会话 3. 权限问题——检查会话存储目录权限
6.7.5 实践示例:金融分析项目配置
以下是一个金融分析项目的完整记忆架构示例。
项目目录结构
finance-analysis/
├── AGENTS.md # 项目级记忆(L1)
├── config/
│ ├── data_sources.md # 数据源配置(L2)
│ ├── coding_standards.md # 代码规范(L2)
│ └── compliance_rules.md # 合规要求(L2)
├── data/
│ ├── client_profiles.jsonl # 客户画像数据(L3)
│ └── market_events.yaml # 市场事件记录(L3)
├── WORKING_PLAN.md # 工作计划(动态更新)
└── REMEMBER.md # 经验教训(持续积累)AGENTS.md 示例
# 金融分析系统
## 项目概述
为理财顾问提供客户画像分析和投资建议工具。
## 技术栈
- Python 3.11 + Pandas + NumPy
- 数据源:Wind API、同花顺接口
- 存储:SQLite(开发)/ PostgreSQL(生产)
## 核心约束
- 所有金额单位:人民币元
- 日期格式:YYYY-MM-DD
- 收益率保留 2 位小数
## 按需配置
@config/data_sources.md
@config/coding_standards.md
@config/compliance_rules.md
## 工作状态
@WORKING_PLAN.md
## 经验教训
@REMEMBER.mdREMEMBER.md 示例
## 常见错误
- 股票代码查询时,上交所用 .SS 后缀,深交所用 .SZ 后缀
- 日期范围查询时,注意中国节假日导致的数据缺失
- 处理财报数据前,先检查会计准则变更
## 最佳实践
- 每次 API 调用后检查返回状态码
- 大量数据处理使用分页,避免内存溢出
- 敏感数据(客户身份证号)必须脱敏处理
## 技术决策记录
### 2026-01-25:风险评估模型选型
- 决策:采用问卷 + 行为分析双轨制
- 原因:单一问卷无法反映真实风险承受能力
- 参考:客户在 2024 年熊市中的实际行为数据通过这套机制,Opencode 能够在会话间保持记忆连续性——不仅记得当前对话,还记得整个项目的背景、规范和历史经验。
本节小结
| 章节 | 核心概念 | 实践要点 |
|---|---|---|
| 6.5 | 情景记忆 | 记录决策轨迹,支持元认知演化 |
| 6.6 | Agentic RAG | 四大能力 + 四种模式,GraphRAG 提升关系推理 |
| 6.7 | Opencode 实践 | 三层信息架构,主动压缩策略 |