8.4 Skills 使用实践
前两节分别介绍了 Skill 的文件结构和匹配激活机制。本节进入实操层面,覆盖 Skill 从创建、安装到调试的完整流程。以下以一个财报分析 Skill 为例,逐步演示每个环节。
8.4.1 创建自定义 Skill
创建 Skill 分三步:规划目录、编写 SKILL.md、放置到正确位置。
步骤一:规划 Skill 目录
先确定 Skill 需要哪些文件。以财报分析 Skill 为例,目录结构如下:
financial-report-analyzer/
├── SKILL.md # 指令文件(必需)
├── scripts/
│ └── calculate_ratios.py # 财务比率计算脚本
└── references/
└── financial-metrics.md # 核心财务指标定义三个组成部分各有分工:
| 文件 | 作用 | 是否必需 |
|---|---|---|
| SKILL.md | 定义 Skill 的触发条件、执行步骤和输出格式 | 是 |
| scripts/ | 存放可执行脚本,由 Skill 指令调用 | 否 |
| references/ | 存放参考资料,为智能体提供领域知识 | 否 |
步骤二:编写 SKILL.md
SKILL.md 由两部分组成:YAML 前置元数据和 Markdown 正文。
YAML 前置元数据定义 Skill 的基本属性:
---
name: financial-report-analyzer
description: >
Analyzes financial statements and calculates key ratios.
Use when the user asks to analyze financial reports,
calculate financial ratios, or evaluate company
financial health.
allowed-tools: Bash(python *) Read Grep
---三个字段的含义:
| 字段 | 作用 | 编写要点 |
|---|---|---|
| name | Skill 的唯一标识 | 用英文短横线分隔,全小写 |
| description | 触发匹配的依据 | 覆盖所有可能的用户表述方式 |
| allowed-tools | Skill 可使用的工具白名单 | 遵循最小权限原则 |
description 直接决定 Skill 能否被正确触发。它必须包含用户可能使用的关键词和短语。上例中同时写了 analyze financial reports、calculate financial ratios、evaluate company financial health 三种表述,覆盖了常见的用户意图。
Markdown 正文定义执行逻辑。以下是一个完整示例:
# 财报分析流程
## 输入
用户提供公司名称或股票代码,以及需要分析的维度。
## 执行步骤
1. 读取用户指定的财务数据文件,或从项目目录中搜索相关文件
2. 运行 `./scripts/calculate_ratios.py` 计算核心财务指标
3. 参考 `./references/financial-metrics.md` 中的指标定义和行业基准
4. 按照下方输出格式生成分析报告
## 核心指标
- 盈利能力:ROE、ROA、毛利率、净利率
- 偿债能力:资产负债率、流动比率、速动比率
- 运营效率:总资产周转率、应收账款周转率、存货周转率
## 输出格式
生成 Markdown 格式的分析报告,包含以下部分:
- 公司概况(1-2 句)
- 各维度指标计算结果(表格)
- 与行业平均水平的对比
- 综合评价(3-5 句)
将报告保存到 `output/` 目录。SKILL.md 的正文应当结构清晰、步骤明确。避免含糊指令(如「适当分析」),改用具体动作(如「计算 ROE、ROA、毛利率三个指标」)。智能体的执行质量与指令的精确程度正相关。
步骤三:放置到正确位置
Skill 文件夹的存放位置决定其作用范围:
| 位置 | 作用范围 | 路径示例 |
|---|---|---|
| 项目级 | 仅当前项目可用 | .opencode/skills/financial-report-analyzer/ |
| 个人级 | 当前用户所有项目可用 | ~/.config/opencode/skills/financial-report-analyzer/ |
项目级 Skill 随代码仓库一起版本管理,团队成员 clone 仓库后即可共享。个人级 Skill 存放在用户主目录下,适合跨项目通用的工具。
将文件夹复制到对应路径后,智能体下次启动时会自动发现并加载该 Skill 的名称和描述。
8.4.2 使用 skill-creator 快速创建
手动创建 Skill 需要记住目录结构和 YAML 格式。Opencode 提供了 /skill-creator 命令,通过交互式对话自动生成 Skill 文件。
使用流程如下:
你:/skill-creator
智能体:请描述你想创建的 Skill 的功能。
你:我需要一个分析上市公司财报的 Skill,能计算盈利能力、
偿债能力和运营效率三类指标,并生成结构化报告。
智能体:好的,我来帮你创建这个 Skill。
- 名称:financial-report-analyzer
- 触发描述:分析财务报表、计算财务比率、评估企业财务状况
- 需要的工具权限:Bash(python *)、Read、Grep
- 需要辅助脚本吗?
你:需要一个 Python 脚本计算财务比率。
智能体:已创建以下文件:
.opencode/skills/financial-report-analyzer/SKILL.md
.opencode/skills/financial-report-analyzer/scripts/calculate_ratios.py/skill-creator 本身也是一个 Skill。它根据用户的自然语言描述,自动生成规范的 SKILL.md 和配套文件。对于不熟悉 YAML 语法的用户,这是最快的入门方式。
8.4.3 安装社区 Skills
除了自行创建,还可以安装他人开发的 Skills。有三种安装途径。
通过 skills.sh 安装
skills.sh 是一个 Skill 包管理工具,可以从 GitHub 仓库直接安装:
npx skills add owner/repo该命令会将指定仓库中的 Skill 文件下载到本地 .opencode/skills/ 目录。
通过 Plugin 系统安装
Opencode 的 Plugin 系统支持从插件市场安装包含 Skills 的插件包:
/plugin marketplace add anthropics/skills
/plugin install example-skills@anthropic-agent-skillsPlugin 安装的优势在于统一管理——一个 Plugin 可以同时包含多个 Skills、Agents 和 MCP 配置,作为一个整体进行版本控制和更新。
手动安装
最直接的方式是将 Skill 文件夹复制到对应路径:
# 从 GitHub 克隆后,复制到项目级目录
cp -r downloaded-skill/ .opencode/skills/
# 或复制到个人级目录
cp -r downloaded-skill/ ~/.config/opencode/skills/安装第三方 Skill 前,务必检查 SKILL.md 的 allowed-tools 字段和 scripts 目录下的脚本内容。恶意 Skill 可能通过 Bash 工具执行危险操作。只从可信来源安装 Skill。
8.4.4 Skills 调用方式
Skill 有两种触发方式:手动调用和自动触发。
手动调用
在对话中输入斜杠命令,直接指定要使用的 Skill:
/financial-report-analyzer 分析贵州茅台 2024 年年报斜杠后面是 Skill 的 name 字段值,空格后面的文本作为参数传递给 Skill。
自动触发
当用户的请求与某个 Skill 的 description 语义匹配时,智能体会自动激活该 Skill,无需用户显式调用:
你:帮我分析一下比亚迪的财务状况
智能体:[自动激活 financial-report-analyzer Skill]
我来为你分析比亚迪的财务数据...自动触发依赖模型对用户意图和 Skill 描述的语义理解。description 写得越精确,触发越准确。
参数传递
Skill 内部通过预定义变量接收用户输入:
| 变量 | 含义 | 示例 |
|---|---|---|
$ARGUMENTS |
用户传入的完整参数文本 | “分析贵州茅台 2024 年年报” |
$1、$2… |
按空格分割的各参数 | $1 = “分析”,$2 = “贵州茅台” |
在 SKILL.md 中可以引用这些变量。例如:
根据用户的请求 $ARGUMENTS,执行以下分析流程...8.4.5 高级特性
掌握基本用法后,以下三个高级特性可以进一步增强 Skill 的能力。
动态上下文注入
使用 !`command` 语法,在 Skill 加载时执行 Shell 命令,将命令输出注入到上下文中:
当前项目中的数据文件:
!`find ./data -name "*.csv" -o -name "*.xlsx" | head -20`
请根据上述文件列表,选择与用户请求相关的数据文件进行分析。Skill 被激活时,find 命令先执行,其输出替换到 SKILL.md 文本中。智能体看到的是实际的文件列表,而非命令本身。这使 Skill 能根据项目的实时状态调整行为。
子智能体执行
在 YAML 前置元数据中设置 context: fork,让 Skill 在独立的上下文环境中运行:
---
name: heavy-analysis
description: Performs resource-intensive financial analysis
context: fork
allowed-tools: Bash(python *) Read Write
---context: fork 的效果是创建一个子智能体(Subagent),拥有独立的上下文窗口。子智能体执行完毕后,只将最终结果返回给主对话。
这适用于需要大量中间步骤的任务。中间步骤的上下文消耗被隔离在子智能体内,不会挤占主对话的上下文空间。
context: fork 的运行方式是:主对话将 Skill 的完整指令交给子智能体,子智能体在独立空间中完成工作,只向主对话返回最终成果。中间过程不进入主对话的上下文,从而节省上下文资源。
字符串替换变量
除了 $ARGUMENTS,Skill 还支持以下动态变量:
| 变量 | 含义 |
|---|---|
${SESSION_ID} |
当前会话的唯一标识 |
${MODEL} |
当前使用的模型名称 |
${PWD} |
当前工作目录路径 |
这些变量在 Skill 加载时自动替换为实际值,用于在指令中引用运行时环境信息。
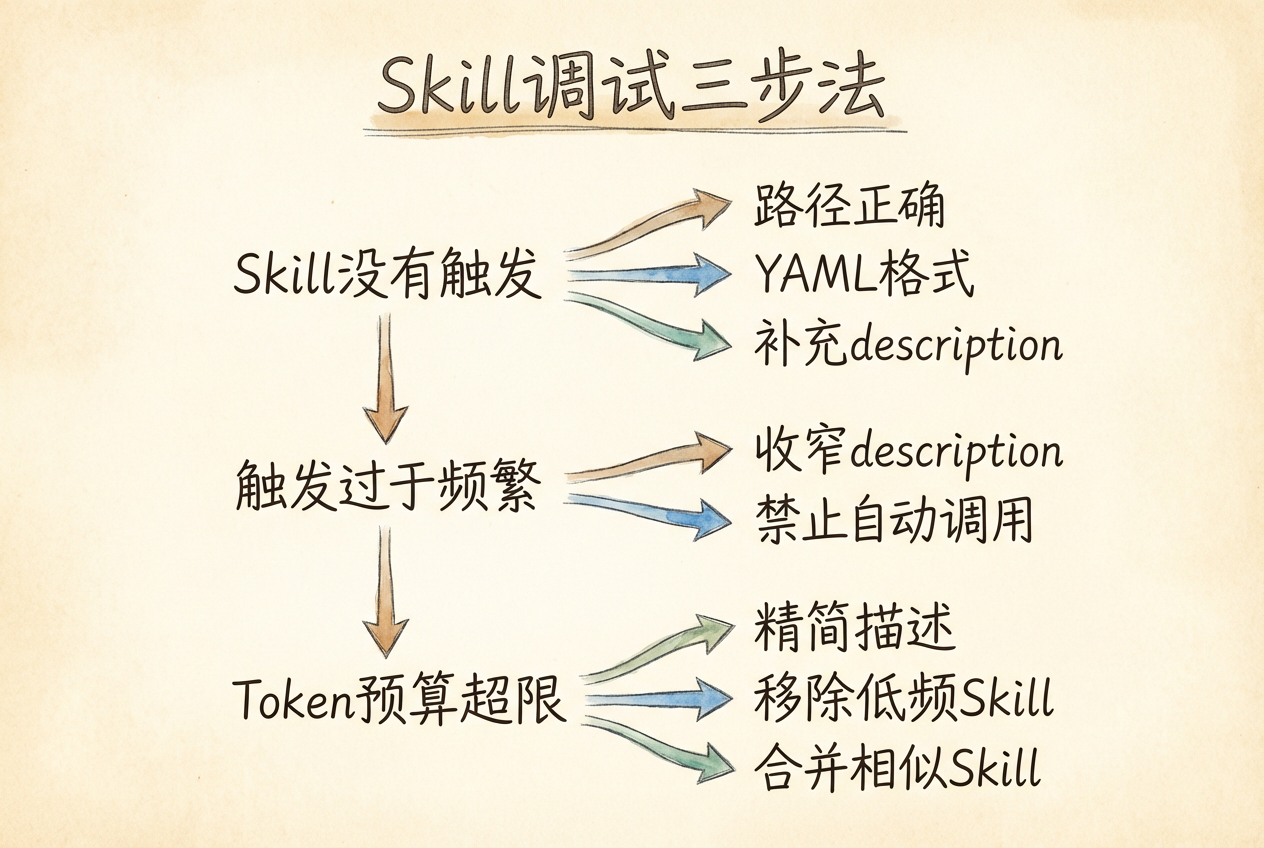
8.4.6 调试与优化
Skill 在使用中可能遇到三类问题。以下是对应的排查方法。
Skill 没有触发
最常见的原因是 description 中缺少用户实际使用的关键词。
排查步骤:
- 确认 Skill 文件夹放在正确路径下(
.opencode/skills/或~/.config/opencode/skills/) - 检查 SKILL.md 的 YAML 格式是否正确(注意缩进和冒号后的空格)
- 在 description 中补充更多同义表述
例如,用户说「看看这家公司赚不赚钱」,而 description 只写了 analyze financial reports。两者语义相关但措辞差距较大,模型可能无法匹配。解决办法是在 description 中加入更口语化的表述,如 evaluate profitability、check if a company is profitable 等。
Skill 触发过于频繁
如果某个 Skill 的 description 过于宽泛,可能在不相关的场景中也被激活。
两种处理方式:
- 收窄 description 的语义范围,使用更具体的限定词
- 在 YAML 中添加
disable-model-invocation: true,关闭自动触发,仅保留手动调用
---
name: financial-report-analyzer
description: ...
disable-model-invocation: true
---Token 预算超限
当项目中 Skill 数量较多时,即使只加载第 1 层(名称和描述),累积消耗也不可忽视。
优化策略:
| 策略 | 具体做法 |
|---|---|
| 精简 description | 控制在 2-3 句话以内,去掉冗余修饰 |
| 移除不常用 Skill | 将低频 Skill 移出 .opencode/skills/ 目录 |
| 合并相似 Skill | 将功能重叠的 Skill 合并为一个 |
单个项目中活跃 Skill 建议控制在 5-10 个以内。超过这个数量时,应评估哪些 Skill 的使用频率较低,将其归档或移至个人级目录备用。
8.4.7 四种基础设计模式
根据 Skill 的主要功能,可以归纳为四种设计模式。
模式一:脚本自动化
Skill 的核心是调用一个或多个脚本,完成特定计算任务。
适用场景:财务比率计算、数据格式转换、统计检验
关键特征:SKILL.md 中包含明确的脚本调用指令
典型结构:SKILL.md + scripts/calculate.py模式二:读取-处理-写入
Skill 读取输入文件,按规则处理内容,写入输出文件。
适用场景:财报摘要生成、数据清洗、格式标准化
关键特征:定义明确的输入格式和输出格式
典型结构:SKILL.md + references/template.md模式三:搜索-分析-报告
Skill 先在项目中搜索相关信息,分析后生成报告。
适用场景:政策影响评估、行业对标分析、风险排查
关键特征:使用 Grep/Glob 搜索 + Read 读取 + Write 输出
典型结构:SKILL.md + references/analysis-framework.md模式四:命令链执行
Skill 按固定顺序执行一系列命令,形成自动化流水线。
适用场景:数据采集-清洗-分析-可视化全流程
关键特征:多个 Bash 命令顺序执行,前一步输出为后一步输入
典型结构:SKILL.md + scripts/step1.py + scripts/step2.py四种模式并非互斥。一个复杂的 Skill 可能同时包含多种模式的特征——先搜索数据文件(模式三),再调用脚本计算(模式一),最后按模板生成报告(模式二)。