9.2 文本的数字化表示:Tokenizer 原理
计算机只能处理数字。无论是加法运算还是图像识别,底层都是 0 和 1 的计算。大语言模型也不例外——它无法直接理解「央行宣布降准」这几个汉字,必须先把文字转换成数字序列,才能进行后续处理。
这个转换过程的核心工具叫 Tokenizer(分词器)。它决定了模型如何处理文本,是理解大语言模型工作原理的基础概念。
9.2.1 为什么需要 Tokenizer
文本到数字的桥梁
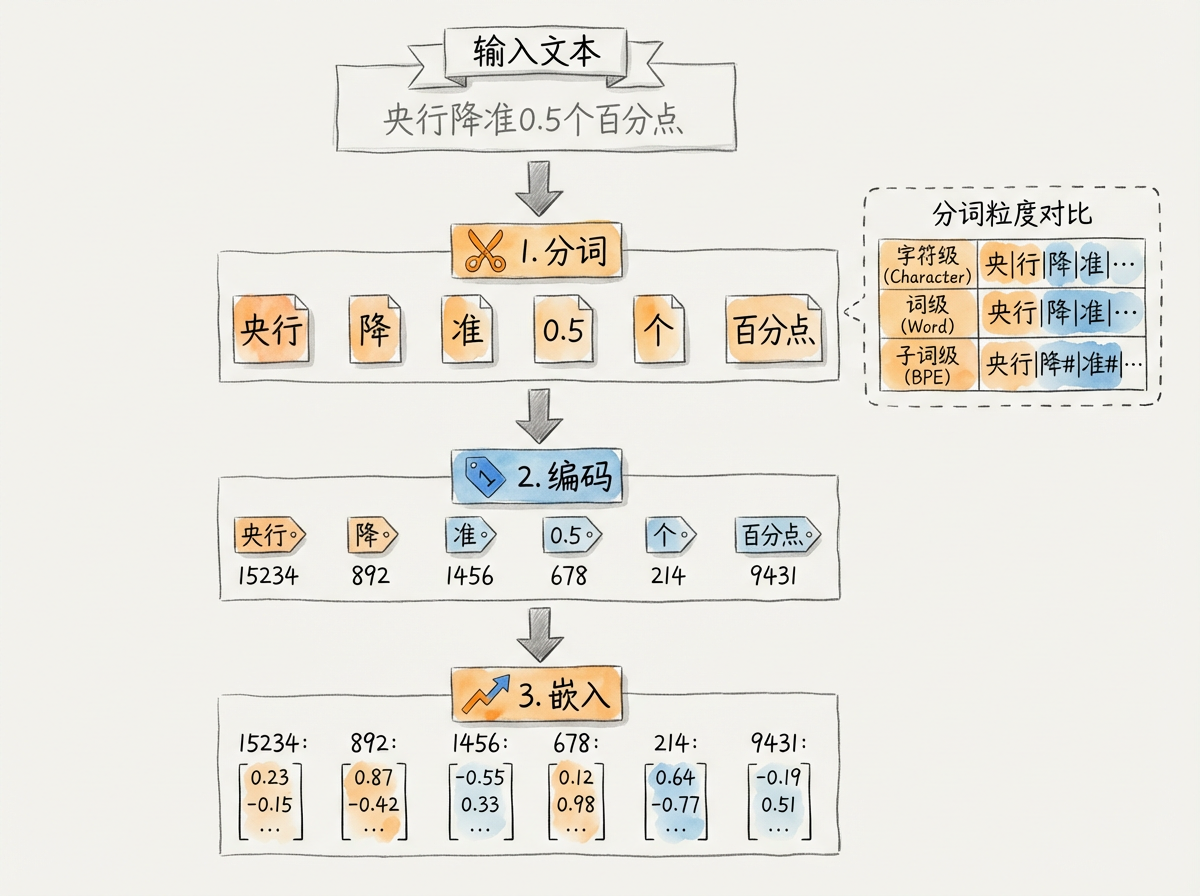
Tokenizer 的核心任务是建立文本和数字之间的映射关系。这个过程分三步:
- 分词:把连续的文本切分成离散的片段(Token)
- 编码:把每个 Token 映射到一个唯一的数字 ID
- 嵌入:把数字 ID 转换成模型可以运算的向量
用一个具体例子说明:
原始文本: "央行降准0.5个百分点"
第一步 分词:
["央行", "降", "准", "0", ".", "5", "个", "百分点"]
第二步 编码:
[15234, 892, 1456, 15, 13, 20, 156, 28934]
第三步 嵌入:
[[0.12, -0.34, ...], [0.56, 0.23, ...], ...] # 每个 ID 对应一个向量Token(词元)是模型处理文本的基本单位。它不一定是一个完整的词,可能是一个字、一个词的一部分,甚至是一个标点符号。Token 的划分方式直接影响模型的理解能力和处理效率。
为什么不直接按字符处理
最简单的方案是把每个字符作为一个 Token。对于英文,就是 26 个字母加标点;对于中文,就是成千上万个汉字。这种方案看似直观,但存在两个问题:
第一,序列太长。一篇 1000 字的财报摘要,按字符切分就是 1000 个 Token。模型处理序列的计算量与长度的平方成正比,序列越长,计算越慢。
第二,语义被切碎。「百分点」是一个完整的金融术语,切成「百」「分」「点」三个字符后,模型需要从上下文重新推断它们合在一起的含义,增加了理解难度。
为什么不直接按词处理
另一个方案是按完整的词切分。英文天然有空格分隔,中文可以用分词工具。这种方案保留了语义完整性,但也有问题:
第一,词表太大。金融领域有大量专业术语:「逆回购」「MLF」「LPR」「社融」「同业拆借」……加上各类公司名、产品名,词表规模会膨胀到几十万甚至上百万。词表越大,模型参数越多,训练和推理成本越高。
第二,无法处理新词。如果训练时没见过某个词,模型就完全不认识。这在金融领域尤其麻烦——每年都有新的政策术语、金融产品名称出现。
9.2.2 分词的三种粒度
根据切分的精细程度,分词策略分为三类:
| 粒度 | 示例 | 词表大小 | 序列长度 | OOV 问题 |
|---|---|---|---|---|
| 字符级 | 「央」「行」「降」「准」 | 极小(几千) | 极长 | 无 |
| 词级 | 「央行」「降准」 | 极大(几十万) | 较短 | 严重 |
| 子词级 | 「央行」「降」「准」 | 适中(3-10 万) | 适中 | 轻微 |
OOV(Out-of-Vocabulary,词表外词)指模型词表中没有收录的词。遇到 OOV 时,词级分词只能用一个特殊的「未知词」符号代替,丢失全部语义信息。这在金融领域问题尤其突出——新股代码、新产品名称、新政策缩写都可能触发 OOV。
字符级分词(Character-level)
把每个字符作为独立的 Token。
优点:词表小,永远不会遇到 OOV。 缺点:序列太长,语义碎片化。
对于中文,一个汉字就是一个 Token;对于英文,每个字母是一个 Token。「interest rate」这个词在字符级下会被切成 13 个 Token(含空格),模型需要学会把这些字母组合起来理解「利率」的含义。
词级分词(Word-level)
按完整词切分。英文依靠空格,中文需要分词工具(如 jieba)。
优点:语义完整,序列短。 缺点:词表巨大,OOV 严重。
金融领域的专业术语多,词级分词的词表会极为庞大。更麻烦的是,一个新出现的术语(如某只新股的名称)会直接变成未知词。
子词级分词(Subword-level)
现代大语言模型普遍采用的方案。它的核心思想是:高频词保留完整,低频词拆成更小的片段。
例如,「央行」是高频词,保持完整;「逆周期」可能拆成「逆」「周期」;一个罕见的公司名可能被拆成若干个字符组合。
这种方案在词表大小、序列长度和 OOV 处理之间取得了平衡。即使遇到训练时没见过的词,子词分词也能把它拆成见过的片段,保留部分语义信息。
9.2.3 BPE 算法原理
BPE(Byte Pair Encoding,字节对编码)是最流行的子词分词算法,GPT 系列模型使用的就是 BPE 的变体。它的核心思想很直观:从字符开始,反复合并最常一起出现的字符对,直到达到预设的词表大小。
算法步骤
以一个简化的例子说明。假设训练语料只有三句话:
"央行降准"(出现 5 次)
"央行加息"(出现 3 次)
"降准预期"(出现 2 次)第一步:初始化
把所有文本拆成字符,统计每个字符的出现频率:
初始词表: {"央", "行", "降", "准", "加", "息", "预", "期"}
字符频率:
央: 8 次, 行: 8 次, 降: 7 次, 准: 7 次
加: 3 次, 息: 3 次, 预: 2 次, 期: 2 次第二步:找出最高频字符对
扫描语料,统计相邻字符对的出现频率:
字符对频率:
(央, 行): 8 次 ← 最高频
(降, 准): 7 次
(加, 息): 3 次
(预, 期): 2 次第三步:合并最高频对
把「央」和「行」合并成一个新 Token「央行」,加入词表:
更新后词表: {"央行", "央", "行", "降", "准", "加", "息", "预", "期"}第四步:重复合并
重新统计字符对频率,继续合并次高频的「降准」:
更新后词表: {"央行", "降准", "央", "行", "降", "准", "加", "息", "预", "期"}如此反复,直到词表达到预设大小(如 50,000 个 Token)。
为什么 BPE 有效
BPE 的关键优势在于它自动学习了语言的统计规律:
- 高频组合会被合并成完整 Token,如「央行」「降准」
- 低频组合保留字符级表示,保证任何新词都能处理
- 词表大小可控,不会无限膨胀
对于金融文本,BPE 会自动识别并合并常见术语。「存款准备金率」可能被分成「存款」「准备」「金」「率」四个 Token——虽然不是完美的切分,但每个片段都保留了部分语义,模型可以从上下文理解完整含义。
不同模型的 Tokenizer 切分结果可能不同。同样一句话,GPT-4 可能切成 10 个 Token,Claude 可能切成 12 个。这是因为它们的训练语料和词表不同。评估模型成本时,需要使用对应模型的 Tokenizer 计算 Token 数量。
9.2.4 其他分词算法
除了 BPE,还有几种常见的子词分词算法:
WordPiece
由 Google 开发,BERT 系列模型使用。与 BPE 的主要区别在于合并策略:
- BPE 合并频率最高的字符对
- WordPiece 合并能最大化语言模型似然的字符对
实践中两者效果接近。WordPiece 的一个特点是用「##」前缀标记非词首的子词。例如「playing」会被切成「play」和「##ing」。
Unigram Language Model
由 Google 提出的另一种方法。它从一个较大的初始词表开始,逐步删除对语言模型影响最小的词,直到词表缩小到目标大小。与 BPE 的从小到大策略相反,Unigram 采用从大到小的删减策略。
SentencePiece
严格来说,SentencePiece 不是一种分词算法,而是一个分词工具库。它的特点是:
- 直接在原始文本上训练,不依赖预分词
- 把空格也作为普通字符处理(用特殊符号「▁」表示)
- 支持 BPE 和 Unigram 两种算法
这使得 SentencePiece 能统一处理各种语言,不需要针对每种语言设计预处理规则。
| 算法 | 使用模型 | 特点 |
|---|---|---|
| BPE | GPT 系列、LLaMA | 简单高效,工业标准 |
| WordPiece | BERT、DistilBERT | 基于似然合并 |
| Unigram | T5、ALBERT | 从大词表删减 |
| SentencePiece | 多语言模型 | 语言无关,统一处理 |
9.2.5 Token 与模型能力的关系
Tokenizer 的设计直接影响模型的多项能力指标。
上下文窗口的真实容量
模型的上下文窗口以 Token 数量计算,而非字符或字数。Claude 3.5 Sonnet 的上下文窗口是 200K Token,这个数字对应多少实际文字,取决于 Tokenizer 的切分效率。
对于英文,1 个 Token 大约对应 4 个字符,即 0.75 个单词。一篇 1000 词的英文文章约占用 1300 个 Token。
对于中文,1 个 Token 大约对应 1.5-2 个汉字。一篇 1000 字的中文文章约占用 500-700 个 Token。
上下文容量估算:
Claude 3.5 Sonnet (200K Token):
- 英文: 约 15 万词 / 约 50 万字符
- 中文: 约 30-40 万字
GPT-4 Turbo (128K Token):
- 英文: 约 10 万词
- 中文: 约 20-25 万字中文的 Token 效率通常高于英文,这与中文的信息密度有关。一个汉字承载的语义信息通常比一个英文字母多。在处理同等信息量的文本时,中文占用的 Token 数更少。这意味着中文用户在相同的上下文窗口限制下,可以输入更多的内容。
Token 计费与成本控制
API 调用按 Token 计费。输入和输出分别计价,输出通常比输入贵 2-4 倍。
| 模型 | 输入价格 | 输出价格 |
|---|---|---|
| Claude 3.5 Sonnet | $3 / 百万 Token | $15 / 百万 Token |
| GPT-4o | $2.5 / 百万 Token | $10 / 百万 Token |
| Claude 3 Opus | $15 / 百万 Token | $75 / 百万 Token |
一个金融问答系统,假设每次请求平均:
- 系统提示:500 Token
- 用户问题:100 Token
- 检索文档:2000 Token
- 模型回答:500 Token
则每次请求消耗 2600 输入 Token + 500 输出 Token。使用 Claude 3.5 Sonnet,每次成本约:
输入成本: 2600 / 1,000,000 × $3 = $0.0078
输出成本: 500 / 1,000,000 × $15 = $0.0075
单次总成本: $0.0153(约 0.11 元人民币)日均 1000 次请求,月成本约 3300 元。
在设计 RAG 系统时,检索返回的文档片段是成本的主要来源。返回 5 个 500 Token 的片段意味着每次请求增加 2500 输入 Token。平衡检索数量和成本是系统设计的重要考量。
9.2.6 Tokenizer 的局限性
尽管子词分词已经是当前的最佳实践,它仍有一些固有局限:
对数字和代码不友好
Tokenizer 通常把每个数字单独切分。「2024」可能被切成「20」「24」或「2」「0」「2」「4」。这导致模型对数字的理解不如对文字那么精确——它很难把「2024」理解为一个完整的年份。
在金融场景中,数字至关重要。股价、汇率、收益率都是精确到小数点的数字。模型在处理这些数字时,偶尔会出现计算错误或数字混淆。
对专业术语切分不理想
即使是高频金融术语,也可能被切分得不够理想。「逆回购利率」可能被切成「逆」「回」「购」「利率」四个 Token,而非「逆回购」「利率」两个 Token。模型需要从上下文学习这些片段的组合含义。
跨语言一致性问题
多语言模型的 Tokenizer 需要平衡各语言的表达效率。有些模型对英文优化更多,导致其他语言的 Token 效率较低。选择模型时,可以测试一下目标语言的 Token 效率。