9.5 向量数据库与索引机制
前几节介绍了向量嵌入的概念——把文本转换成高维空间中的坐标。本节深入探讨:这些向量存储在哪里?如何高效检索?
9.5.1 向量数据库的定义与功能
向量数据库(Vector Database)是专门为存储和检索高维向量而设计的数据库系统。它与传统关系型数据库有根本性区别。
传统数据库(如 MySQL、PostgreSQL)擅长处理结构化数据:姓名、日期、金额等字段,通过精确匹配或范围查询定位记录。当你执行 SELECT * FROM stocks WHERE price > 100 时,数据库按字段值筛选,返回符合条件的行。
向量数据库解决的是另一类问题:给定一个查询向量,找出数据库中与它最相似的 K 个向量。这里没有精确匹配,只有相似度排序。
| 查询类型 | 传统数据库 | 向量数据库 |
|---|---|---|
| 精确查找 | 查询股票代码 600519 的收盘价 | 不适用 |
| 范围查询 | 查询市盈率在 10-20 之间的股票 | 不适用 |
| 语义搜索 | 不适用 | 找出和「央行降息影响」语义最相近的研报段落 |
| 相似推荐 | 不适用 | 根据某篇研报,推荐内容相似的其他研报 |
向量数据库承担三项核心功能:
存储(Storage)
向量数据库存储的是高维浮点数组。一篇文档经过嵌入模型处理后,变成一个包含数百到数千个浮点数的向量。数据库需要高效地将这些向量持久化到磁盘,同时支持快速加载到内存。
索引(Indexing)
索引是向量数据库的核心技术。原始向量存储后,数据库会构建索引结构,使检索时无需遍历全部数据。索引算法决定了检索速度和召回率的平衡。
检索(Retrieval)
检索是向量数据库的最终目的。给定查询向量,数据库利用索引结构快速定位最相似的 K 个向量,返回结果及相似度分数。
向量数据库的本质功能:在海量高维向量中,快速找到与查询向量最相似的若干条目。这是语义搜索、推荐系统、RAG 等应用的底层支撑。
9.5.2 最近邻搜索问题
向量检索的数学本质是最近邻搜索(Nearest Neighbor Search)问题。
K 最近邻(K-Nearest Neighbors,K-NN)定义
给定一个查询点 q 和一个包含 n 个点的数据集 D,K-NN 问题要求找出 D 中与 q 距离最近的 K 个点。
在向量数据库语境下,每个「点」是一个文档块的嵌入向量,「距离」通常用余弦相似度或欧氏距离衡量。
暴力搜索的复杂度问题
最直接的方法是暴力搜索(Brute Force):计算查询向量与数据库中每个向量的相似度,按分数排序,取前 K 个。
这个方法简单直观,但计算量巨大。假设数据库有 n 个向量,每个向量维度为 d,则: - 计算一次相似度需要 O(d) 次运算 - 遍历全部向量需要 O(n × d) 次运算
当 n = 1000 万、d = 1024 时,一次查询需要约 100 亿次浮点运算。即使用现代 CPU,也需要数秒才能完成,完全无法满足实时检索需求。
为什么需要近似最近邻(ANN)算法
面对暴力搜索的效率瓶颈,近似最近邻(Approximate Nearest Neighbor,ANN)算法应运而生。
ANN 算法的核心思想是:牺牲少量精度,换取数量级的速度提升。
它不保证找到绝对最近的 K 个邻居,但保证找到的结果足够接近真实答案。实践中,主流 ANN 算法能在毫秒级完成千万级向量库的检索,同时召回率超过 95%——即找到的 Top-10 结果中,有 9.5 个确实是真正的 Top-10。
对于 RAG 应用,这个精度足够了。我们并不需要找到数学意义上绝对最相似的文档,而是需要找到语义高度相关的文档。ANN 算法的微小误差几乎不影响最终生成质量。
9.5.3 HNSW 算法原理
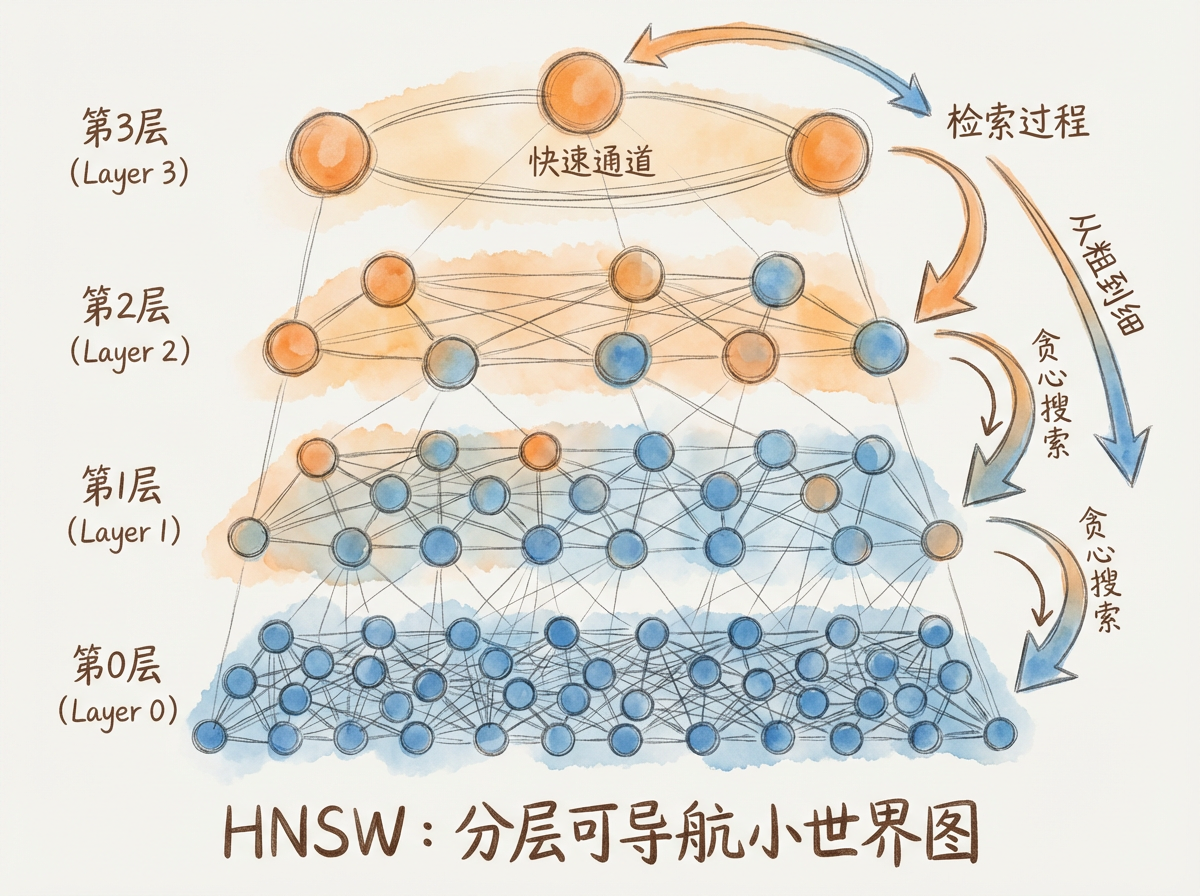
HNSW(Hierarchical Navigable Small World,分层可导航小世界图)是目前最流行的 ANN 索引算法。理解它的原理有助于选择合适的参数配置。
小世界网络的启发
HNSW 的理论基础来自小世界网络理论——在特定的图结构中,任意两个节点之间只需少量跳转即可到达。这意味着通过合理构建连接关系,可以实现高效的节点间导航。
将这个思想应用到向量检索:如果我们能构建一个网络,让语义相近的向量彼此连接,检索时就可以沿着连接跳跃,快速逼近目标,而非逐一遍历。
多层图结构的设计思想
HNSW 的核心创新是引入分层结构:
- 第 0 层(底层)包含全部向量,每个向量与其最近的若干邻居相连
- 更高层只包含部分向量(按概率随机选择),形成更稀疏的快速通道
- 层数越高,向量越少,节点间跨度越大
层级越高,节点越少但跨度越大,形成粗粒度的快速跳转通道;层级越低,节点越密集,支持细粒度的精确定位。
检索过程:从顶层粗定位到底层精确查找
查询向量 q 的检索过程如下:
- 从顶层入口点开始。选择顶层的一个固定入口点作为起点
- 在当前层贪心搜索。沿着边移动到与 q 更相似的邻居,直到无法继续改进
- 下降到下一层。以当前位置为起点,进入更密集的下一层继续搜索
- 重复直到底层。在底层完成最终的精确定位,返回 Top-K 结果
每下降一层,搜索范围缩小,定位精度提高。这种从粗到细的分层策略避免了在底层全量遍历,大幅降低了检索耗时。
性能特点:速度与召回率的权衡
HNSW 的性能受两个关键参数影响:
| 参数 | 含义 | 影响 |
|---|---|---|
| M | 每个节点的最大连接数 | 越大召回率越高,但内存占用和构建时间增加 |
| ef_search | 检索时的候选队列大小 | 越大召回率越高,但检索延迟增加 |
典型配置与性能参考(百万级向量库):
| 配置 | 检索延迟 | 召回率@10 | 适用场景 |
|---|---|---|---|
| M=16, ef=50 | ~5ms | ~92% | 对延迟敏感的实时应用 |
| M=32, ef=100 | ~15ms | ~97% | 平衡选择,推荐默认值 |
| M=48, ef=200 | ~30ms | ~99% | 对召回率要求极高的场景 |
对于金融文档检索场景(通常几万到几十万条向量),HNSW 的默认参数(M=32, ef_search=100)已能满足需求,无需过度调优。优先关注嵌入模型选择和分块策略,它们对检索质量的影响更大。
9.5.4 其他索引算法简介
除 HNSW 外,还有几种常见的 ANN 索引算法,适用于不同场景。
IVF(Inverted File Index):倒排索引思想
IVF 的核心思想是先聚类、后检索:
- 训练阶段:用 K-Means 算法将全部向量聚成若干簇(cluster),每个簇有一个中心点
- 索引阶段:每个向量被分配到最近的簇,建立倒排索引
- 检索阶段:先找到查询向量最近的若干个簇,只在这些簇内搜索
IVF 的优缺点: - 优点:索引构建速度快,内存占用低 - 缺点:簇边界处的向量容易被漏检,召回率不如 HNSW
PQ(Product Quantization):向量压缩
PQ 是一种向量压缩技术,常与 IVF 联合使用(IVF-PQ)。
原理:将高维向量切分成若干段,每段独立量化。例如,1024 维向量切成 8 段,每段 128 维,用 256 个码本向量表示。原本需要 4KB 的向量,压缩后只需 8 字节。
PQ 大幅降低内存占用和计算量,代价是精度损失。适合内存受限但数据量巨大的场景(如十亿级向量库)。
不同算法的适用场景
| 算法 | 数据规模 | 内存 | 召回率 | 推荐场景 |
|---|---|---|---|---|
| HNSW | 百万~千万级 | 高 | 高 | 追求检索质量,内存充足 |
| IVF | 千万~亿级 | 中 | 中 | 大规模数据,平衡方案 |
| IVF-PQ | 亿级以上 | 低 | 较低 | 超大规模,内存受限 |
| Flat(暴力) | 万级以内 | 低 | 100% | 数据量小,对精度要求极高 |
对于本书涉及的金融应用场景(政策文档、研报、论文),数据量通常在十万到百万级,HNSW 是首选。
9.5.5 主流向量数据库
市场上有多种向量数据库产品,各有定位。
Chroma:轻量级,适合学习
Chroma 是 Python 原生的向量数据库,以简洁著称。
特点: - 零配置,pip install chromadb 后立即可用 - 内置多种嵌入模型支持 - 数据默认存储在内存或本地文件 - 不适合生产环境的大规模部署
适用场景:学习向量检索概念、快速原型开发、小型项目。
Qdrant:高性能,支持 MCP
Qdrant 是用 Rust 编写的高性能向量数据库,近年获得广泛采用。
特点: - 性能优异,支持百万级向量的毫秒级检索 - 丰富的过滤条件支持(按元数据筛选) - 提供官方 MCP Server,与 Opencode 集成顺畅 - 支持 Docker 部署,也有托管云服务
适用场景:生产环境、需要与 Opencode 集成的项目。
Pinecone:托管服务
Pinecone 是一款全托管的向量数据库云服务。
特点: - 无需运维,按用量付费 - 自动扩缩容 - 提供免费额度,适合试用 - 数据存储在云端,需考虑数据合规
适用场景:希望快速上线、不想管理基础设施的团队。
Milvus:企业级
Milvus 是 CNCF 孵化的开源向量数据库,面向企业级场景。
特点: - 支持十亿级向量 - 分布式架构,水平扩展 - 多种索引算法可选 - 部署和运维复杂度较高
适用场景:大型企业、海量数据、有专业运维团队。
选型考虑因素
| 因素 | 说明 |
|---|---|
| 数据规模 | 万级以下用 Chroma;百万级用 Qdrant/Pinecone;亿级用 Milvus |
| 部署方式 | 本地开发用 Chroma/Qdrant Docker;生产环境考虑 Pinecone 托管或 Qdrant Cloud |
| 集成需求 | 与 Opencode 集成优先选 Qdrant(有官方 MCP) |
| 预算 | 预算有限选开源方案;追求免运维选托管服务 |
| 数据合规 | 敏感数据需本地部署,避免数据出境 |
对于本书的学习者,推荐从 Qdrant 起步。它兼具易用性和专业性:Docker 一条命令启动,MCP 集成可直接对接 Opencode,性能满足绝大多数学习和小型生产场景。等熟悉了向量检索的完整流程,再根据实际需求评估其他选项。